A year ago, you couldn't vibe code in Lisp. Even the SOTA models
had trouble balancing parentheses, and they'd hallucinate packages
and symbols that didn't exist. A year makes a big difference in this
field, and the latest models are capable of vibe coding moderately
sized programs in syntactically correct Lisp.
I have been experimenting with vibe coding in Common Lisp and I'm
hooked. It is a blast. It is like having on hand a talented
undergraduate who just took a Lisp course. If you give him
small enough, focused tasks, he will churn out passable code. If
you give him a good chunk of legacy code, he will churn out more
code in the legacy style. The models are not good enough to do a
full rewrite of a large codebase, but they are good enough to
handle a small library with supervision.
I find myself accepting a large amount of code with just a glance—if
it passes the Lisp reader, compiles, and the tests pass, I accept
it. Unlike the code of a year ago, the generated code these days is
far less buggy, and the models are pretty good at debugging their
own code. I'll do spot checks on the code, but I don't bother
reading it line by line unless I see something odd. If the model
generates code in a style I don't like, I'll ask it to rewrite the
code to be more to my liking.
But frankly, you don't need to read the code at all. If there is a
good test suite, the model will generate code that passes tests. If
the code is functionally correct, it doesn't matter if the code is
pretty. In one way, it doesn't matter if the code is easy for a
human to read and maintain because we ask the model to maintain it.
We treat the code as a black box and we constrain it to pass the
tests. (We accept machine code largely unread.)
Failure Modes
By far the most common failure mode is the model getting the number
of closing parentheses wrong. The tail end of a block of code is
usually a bunch of closing parentheses, and the model will be
tokenizing them in groups of 2 or 3. But the likelihood of the "))"
token isn't very much different from the likelihood of the ")))"
token, so the model will sometimes grab the wrong one.
Depending on the model and the agent, when it tries to recover from
the ensuing read error, it will re-compute the tokens in the output.
It sometimes will thrash as it tries to balance parentheses,
adding and removing them from various places in the code. (Sort of
like a noob Lisp programmer.) Some models are more susceptible to
this than others. I have found that the solution here
is to pause the agent and manually fix the parentheses when the
agent starts to thrash.
Vibe Coding Workflow
I've been using Copilot CLI and Gemini CLI to vibe code in Common
Lisp. I start with a blank project directory and create an .asd
file that loads the packages.lisp file and the main file for the
project (which can start out as a "hello world"). Basically, make a
minimal project that you can load with ASDF or Quicklisp.
The models can work at moderate levels of abstraction, but they do
better if there is existing code supporting the abstraction level,
and this suggests a `bottom-up` approach to the problem rather than
a `stratified` design. But the models are actually quite capable of
starting at a moderate level of abstraction right from the get-go.
So starting with a minimal project, I boot up the model and ask it
to write the first things needed for the project—some data
structures, some utilities, a few tests. The very simple stuff that
is easy for the model to do ab initio. Then I ask the model to
write a minimal main function that will implement the basic
functionality of the project—a command loop, a server, what-have-you—with
stubs for everything. Once a framework is in place, the
models are easily able to extend it.
The agents will get into a loop of adding code, adding tests, and
running all the tests. They will debug any test failures and only
consider a task to be complete when all the tests pass.
The model does not write great code, and you will accumulate
technical debt if you accept it as is. But the model can write code
that works and passes the tests. It is a good idea to pause during
development and simply ask the model to find the technical debt in
the code, enumerate it, and rank it in order of importance. Then
you ask the model to address each item in turn and the model will
clean up the code. After a couple of iterations of cleanup, the
code will look no worse than what I've seen in many professional
codebases.
There are sort of two modes that you operate in: one is to modify
the existing code (e.g. refactor) without disturbing the
functionality; the other is to extend the functionality without
disturbing the core operation. It is important to spend enough time
refactoring and cleaning up. But the model is good at generating
potential refactorings, and it is not good at knowing when to call
it quits. It will happily churn away at your code making it
`better' and doing more and more trivial refactorings. If you give
the model one particular refactoring task and tell it to do just
that one, it will do a good job.
Refactoring is satisfying in a certain way, but adding features
gives you more instant gratification. The models are good at adding
features and extending existing code, especially if the feature
shares any similarity with existing code.
For more complex features and refactorings, tell the model that you
want a 'plan' for the feature or refactoring. The model will come
up with a multi-step plan, broken down into a series of tasks. The
tasks in the plan are generally small enough to be handled by the
model itself.
The models are good enough to maintain a codebase, so once you
have a project up and running, the model will generally choose file
names and a directory structure that is appropriate to put in
the .asd file. If you get the model started with a test suite, it will
extend the tests as it extends functionality, or you can ask it to
add specific tests.
I have found that building a project by vibe coding it is an
extremely rapid way to prototype. The model can churn out `obvious'
code much faster than I can and it frees me up to think about the
higher level design issues. I can build in a weekend what would
have taken me a month before.
I wanted to run LLM models locally on my machine. I discovered
that llama.cpp is how people run models locally, and that the
popular LLM servers like Ollama and lmstudio and unsloth use
llama.cpp under the hood.
llama.cpp is, of course, written in C++. I don't care for C++ and
I prefer Common Lisp. With the appropriate declarations, Common
Lisp code should be in the same performance ballpark as C++ code.
So I decided to write a Common Lisp implementation of llama.cpp,
which I call llambda.lisp.
It is available
on GitHub.com/jrm-code-project/llambda
If you care to contribute, it could use routing for architectures
other than gemma, GPU support, NPU support, and other features.
Recently I stumbled on a funny kind of race in distributed systems. I believe even the classic texts don't cover that.
Say we have a system S sending commands to a receiver R over network. S maintains network outbox and inbox handled by separate threads. A command is expected to complete with certain result sent back before the deadline, or else S would assume a request timed out. Very basic so far.
However a certain class of commands (and only it) was timing out. They would fail regularly on some networks, sporadically on others and seemingly never on some. Perplexingly they were really simple commands, amounting to little else than sending back a reading of R's internal state. Increasing the command deadline had no apparent effect. Adding logging in places helped little and in fact often resulted in the issue disappearing.
Simplifying it quite a bit the S side looked something like this:
You see now what was happening: S was sending the command, R processing it, sending the reply and S handling the reply before the bookkeeping of outbox process would record the command. Then the response wouldn't match anything and be discarded as orphaned. Later the inbox would timeout the command (not shown).
The bookkeeping wasn't even that heavyweight: just storing some structures and perhaps couple expensive calls to set up a condition variable but that was enough.
Naturally any kind of latency (be it due to network load or extraneous syslog calls) would alleviate that. The fix was to make the code inelegant but correct by registering the command before the send attempt and un-registering in the event of failure.
Lately I've been playing with writing a chatbot library in Common Lisp.
My previous gemini bindings were getting unweildy. I wanted to add the ability to run LLMs on my local machine but it turned out
to be really kind of kludgy, so I decided to start from scratch with multiple back ends in mind.
I've got it to the point where in supports multiple back ends, so now I can prompt local LLMs from Lisp.
Recently I added the ability to recursively launch chatbots that can call each other. Since the chatbots do not share
their contexts, this greatly reduces the context bloat of thet main chat because it can spawn off subtasks to a minion and not
pollute the main context. This also allows you to create a federation of chatbots, each of which specializes in some topic and is overseen by a controlling chatbot that talks to the user.
Chatbots can be serialized and checkpointed, so if one is carrying out an agentic task and Lisp crashes, when we restart
the agentic tasks are restarted as well and pick up where they left off.
IT turns out that recursive chats are a useful abstraction once you figure out how to use them. Basically any prompt you may issue may also want to be issued by an llm and this enables that to happen. It allows you to run subprocesses that would otherwise put junk in your context, for example reading the contents of a lange number of files. If you put that into a rocursive chatbot, it could
slurp up the files into its context without adding tokens to the parent chat.
You can use a recursive chat as a `smart component'. The recursive chat can have a specialized system instruction and can preload its context with relevant information specific to it. It's context doesn't get diluted by the caller's context
I saw that there was some argument over how much slower slot access is than struct access, so
I just decided to measure it naively. I made a two slot sruct and a CLOS version of a CONS cell
with car and cdr slots
and I ran LTAK using regular lists, `lists' made from CLOS conses, and `lists' made from structs.
Here are the results:
D:\repositories\clos-benchmark>sbcl --script run-benchmarks.lisp
Benchmark: ltak over native cons cells, CLOS my-cons nodes, and my-cons-struct nodes
Inputs: x=15 y=9 z=4 repeats=35
Scenario min-ms mean-ms max-ms ratio
--------------------------------------------------------------------
native standard 0.129 0.146 0.186
clos standard 1.346 1.365 1.475 9.37x
struct standard 0.172 0.175 0.179 1.20x
native optimized 0.068 0.069 0.073
clos optimized 0.411 0.414 0.419 6.04x
struct optimized 0.068 0.069 0.073 1.01x
In this naive use case, structs are same as native cons cells, but CLOS objects are one ninth the speed of a struct or cons cell if you just use it unoptimized, and one sixth the speed if optimizations are turned on.
But the CLOS instance is more functional than the cons cell in mimics. For instance, I could add a slot to the class and all the instances would be lazily updated with the new slot. I can also subclass the CLOS class and the selector functions will continue to work. Finally, I can redefine the CLOS closs while I'm developing it and all the instances will be uppdated.
THe machinery to keep all this running is costing us our factor of 9.
But this might be worth the cost if we are running on a network where the bulk of the time will be transmitting the answer down the pipe once it is computed. Taking a few extra milliseconds to compute the answer might be worth the convenience features of CLOS.
Back in the day, the US government had a program called SBIR (Small
Business Innovation Research) that funded small businesses to do
research and development. I recall sitting in our dorm in college,
reading through a giant printed catalog of SBIR grants just to amuse
ourselves by brainstorming solutions over bad pizza.
.
So, I got curious the other day: what does the SBIR landscape look like now?
I can tell you right now: do not even try to read
an SBIR solicitation on your local machine. You are opening yourself
up to a world of absolute, unmitigated pain.
You might think, what harm could there be in simply opening a
file?
Well, in the modern compliance panopticon, any manipulation of digital information that comes from
the govenment has the potential to spawn CUI (Controlled
Unclassified Information). CUI is basically a digital pathogen;
once you download that file, *anything whatsover*
derived from it, including notes and metadata, instantly becomes CUI by
association. The moment you
read an SBIR on your computer, you've infected your
system, rendering you subject to a nightmare of Byzantine federal regulations.
These days, the amount of beurocratic red tape surrounding
CUI is insane. To
even look at the file legally, you need a dedicated, air-gapped machine
completely disconnected from the internet, conforming to a massive, expensive
slew of NIST standards covering everything from hardware-level encryption to
strict access controls.
Alternatively you could contract with a cloud company that offers a
pre-certified "CUI-compliant" environment.
And assuming you actually shell out the cash and jump through the hoops to set
up this digital containment zone just to read a PDF, you must meticulously audit
and account for every single action you take in its presence. Under current
federal auditing logic, you are explicitly assumed to be attempting to defraud
the government unless you can produce a mountain of paper proving otherwise.
Want to bring in a partner to bounce ideas around? You can't just "know a guy."
You have to navigate a labyrinth of federal subcontracting regulations.
I had intended on amusing myself by reading some SBIRs and
daydreaming about solutions that might involve Lisp (an impossibility in the
modern enterprise stack for entirely separate, depressing reasons).
Instead, I quickly discovered I did not
even own the physical hardware required to even read an SBIR without running
afoul of federal regulations.
I wanted to read some clever and inspiring engineering proposals. I ended up reading a lot of very dry and boring
compliance regulations.
Last year I wrote some Lisp related AI apps. There was a syntax highlighter that used the LLM to determine how to colorize and highlight syntax, and a prompt refiner that takes a wimpy LLM prompt and creates more elaborate prompt from them.
I took the apps down last week. They were `vibe coded' and therefore approximate and had bugs (but that's to be expected), but they had a security hole where you could hijack the LLM processing with your own prompt turning my app into an open relay using my API key.
Last week I discovered that my AI spend on video creation was becoming serious. This is odd because I never create AI video. It turned out that my app was being hijacked by a proxy in Luxembourg and was generating videos on my dime.
So I shut down the apps. I knew they had the potential of being abused, and I was willing to tolerate a small amount of abuse, but it didn't occur to me that syntax highlighter could be hijacked to generate gigabytes of video at my expense. Future applications will be careful to obtain the API key from the user.
Metaobject Protocol (MOP) Implementation in CLRHack
The Metaobject Protocol in CLRHack is a high-performance implementation of the Common Lisp Object System (CLOS) integrated into
the .NET 8.0 Common Language Runtime (CLR). It provides a complete meta-compilation pipeline that bridges the gap between dynamic
Lisp semantics and the static CIL (Common Intermediate Language) execution model.
Core Architecture
The MOP is implemented through three primary layers:
The Metaobject Hierarchy (C#): A set of foundational classes in LispBase representing
classes, methods, generic functions, and slot definitions.
The Runtime Engine (MopRuntime): A centralized orchestrator that manages class finalization,
method combination, dispatch caching, and instance allocation.
The Compiler Bridge (Lisp): Transformations in ast.lisp that translate high-level CLOS forms
(defclass, defmethod) into optimized runtime calls.
Instance Representation
Because the CLR type system is strictly single-inheritance and statically defined, CLRHack decouples Lisp-level inheritance from
C# inheritance. All CLOS instances are represented by the StandardObjectInstance class, which contains:
A reference to its ClassMetaobject.
A private object[] storage array for instance slots, indexed by locations calculated during class
finalization.
The Dispatch Pipeline
Generic function invocation is the most complex part of the implementation. When a generic function is called:
Cache Lookup: The DiscriminatingFunction first checks a thread-safe
dispatchCache using an InvocationCacheKey (a stack-allocated struct) to find a previously
computed effective method.
Applicability & Precedence: If the cache misses, the runtime computes all applicable methods and sorts
them based on specializer specificity and the Class Precedence List (CPL).
Method Combination: The ComputeEffectiveMethod logic builds a nested execution chain
following the Standard Method Combination rules:
:around methods are called first, with call-next-method progressing to the next around
method or the main chain.
The main chain executes all :before methods, the primary method, and finally all :after
methods in reverse order.
Fast Invocation: The resulting effective method is compiled into a Func<object[],
object> that uses direct delegate invocation to minimize overhead.
Challenges and Solutions
1. Thread-Safe Non-Local Exits (call-next-method)
Challenge:call-next-method and next-method-p require access to the current
invocation's state (the remaining methods and original arguments). Passing this state through every function call would break
compatibility with standard Lisp function signatures.
Solution: CLRHack utilizes [ThreadStatic] fields in MopRuntime to store the
currentNextMethods and currentArguments. This ensures that even in highly concurrent environments (like a
web server), each OS thread has its own isolated invocation context, allowing call-next-method to function correctly
without state leakage.
2. Forward References and Lazy Finalization
Challenge: Lisp allows classes to refer to superclasses that haven't been defined yet. The runtime must handle
these "zombie" classes without crashing the JIT compiler.
Solution: The system implements a ForwardReferencedClassMetaobject. When a class is defined, it is
automatically finalized (computing its CPL and slot layout). If a superclass is missing, a forward reference is created. The
EnsureFinalized protocol ensures that inheritance is resolved and slot locations are assigned the moment the class is
first instantiated or used in dispatch.
3. Performance Overhead of the "MOP Bridge"
Challenge: A naive implementation of slot-value or generic dispatch using C# reflection or linear
searches is orders of magnitude slower than native C# member access.
Solution: Three distinct optimizations were applied:
O(1) Slot Access: Each ClassMetaobject maintains a SlotDictionary. Slot
names are mapped to physical array indices during finalization, allowing slot-value to perform a direct array access
after a single dictionary lookup.
Compiler Primitives: The compiler identifies SLOT-VALUE and MAKE-INSTANCE
calls and emits direct CIL call instructions to optimized Lisp.MopRuntime methods, bypassing the general
Funcall path.
Zero-Allocation Cache Hits: By making InvocationCacheKey a readonly struct
and avoiding the cloning of the argument array during cache probes, the hot-path for generic function dispatch generates zero
garbage for the .NET Collector.
4. Bootstrapping the COMMON-LISP Package
Challenge: Core CLOS functions like make-instance must be available as symbols in the
COMMON-LISP package before user code runs, but they rely on the MOP runtime being fully initialized.
Solution: A MopRuntime.Initialize() method is injected into the entry point (Main) of
every generated assembly. This method interns the necessary symbols and binds them to GenericFunctionClosureAdapter
objects, ensuring that the MOP is "alive" before the first line of Lisp code executes.
Vibe coding the MOP basically involved feeding chapters 4 and 5 of the Art of the Meta-Object Protocol into the LLM and telling it to make an implementation plan. It came up with a twenty-step plan to bootstrap CLOS. I then spent the rest of the day instructing an agent to take on each task of the twenty-step plan in sequential order. At the end of the day, I had a working MOP
In CLRHack, the condition signaling system is implemented in the Lisp.HandlerControl class within the
LispBase library. It leverages .NET's [ThreadStatic] storage to maintain a per-thread dynamic stack of
active condition handlers.
SIGNAL Implementation
The Signal(object condition) method performs the following logic:
Retrieval: It fetches the activeHandlers list for the current thread. This list is a chain of
[LispBase]Lisp.Handler objects maintained by handler-bind.
Iteration: It iterates linearly through the list from the most recently bound handler to the oldest.
Type Matching: For each handler, it calls IsType(condition, handler.ConditionType).
If the condition is a symbol, it checks for symbol equality (supporting simple symbol-based
conditions).
If the condition is a .NET object, it checks if the handler's type is assignable from the condition's
runtime type (supporting interop with system exceptions).
It treats the symbols T or EXCEPTION as catch-all types.
Handler Invocation: If a match is found:
Recursive Signal Protection: Before calling the handler function, the current handler list is
temporarily shadowed. activeHandlers is set to cell.rest (the handlers bound outside the current
one). This ensures that if the handler itself calls signal, it won't trigger itself recursively.
Execution: The handler's Closure is invoked with the condition object as its argument.
Restoration: A finally block ensures the original activeHandlers list is
restored if the handler returns normally.
ERROR Implementation
The Error(object condition) method build upon Signal:
Signaling Pass: It first invokes Signal(condition). If a handler performs a non-local exit
(e.g., via handler-case), the Error method never returns.
Debugger Entry: If Signal returns normally (meaning all handlers declined), Error
calls EnterDebugger(condition).
Interactive Debugging: The debugger:
Prints the condition and a list of available restarts (retrieved via
RestartControl.GetActiveRestarts()).
Provides a prompt for the user to select a restart, launch the system-level debugger (Visual Studio/Rider), or
abort.
If a restart is selected, it is invoked interactively (potentially gathering arguments from the user).
Final Fallback: If the debugger is exited without invoking a restart, Error throws a C#
Exception to ensure that execution does not continue on an invalid path.
Notable Implementation Decisions and Edge Cases
Handler Shadowing: The decision to pop the handler list during invocation is critical for maintaining Common
Lisp semantics. It prevents infinite loops and ensures that "outer" handlers can handle errors raised within "inner" handlers.
Unified Exception Model: CLRHack attempts to unify Lisp conditions and .NET exceptions. IsType
allows Lisp handlers to catch C# exceptions by their class name or Type object.
Thread Isolation: By using [ThreadStatic] for activeHandlers, CLRHack ensures that
condition signaling is thread-safe. One thread signaling an error will not interfere with the handler state of another thread.
Debugger Capability: The SYSTEM-DEBUGGER option in EnterDebugger is a bridge to
the underlying .NET environment, allowing developers to use professional IDE tools to inspect the state of the Lisp VM when an
unhandled error occurs.
signal and error complete the Common Lisp condition system implementation for CLRHack
In the CLRHack compiler, handler-bind is a primitive form used to register condition handlers in the dynamic
environment. It operates by managing a thread-local list of active handler objects, ensuring that condition signaling follows the
standard Common Lisp search and execution rules.
Handling of handler-bind
When the compiler processes a handler-bind form, it generates CIL code that performs the following steps:
Capture Previous State: It calls Lisp.HandlerControl::GetActiveHandlers() to retrieve the
current list of active handlers and stores it in a frame-local variable.
Construct New List: For each binding, it evaluates the condition type and the handler function (which is
typically a closure). It instantiates a new [LispBase]Lisp.Handler object and conses it onto the current handler
list.
Install New State: It calls Lisp.HandlerControl::SetActiveHandlers(new_list) to update the
dynamic environment for the current thread.
Protected Execution: The body of the handler-bind is wrapped in a CIL .try
block.
Restoration: A finally block is emitted that calls SetActiveHandlers with the
saved list. This ensures that handlers are properly uninstalled, regardless of whether the body completes normally, signals an
error, or performs a non-local exit.
Lexical Non-Local Exits
Handlers in Common Lisp are executed in the dynamic environment of the signaller but have lexical access to the environment
where they were defined. In CLRHack, if a handler function performs a non-local exit (such as a throw or
return-from), the compiler utilizes its exception-based jump mechanism:
If the exit is a throw, it uses the standard CatchThrowException mechanism.
If the exit is a return-from to a block outside the handler closure, the compiler identifies this as a non-local
exit during analyze-environment. It compiles the return-from into a throw of a
BlockExitException, which is subsequently caught by the try/catch frame established by the target
block.
Handler Search
The handler search is performed at runtime by the signal or error functions. These functions retrieve
the active handlers list via HandlerControl.GetActiveHandlers() and iterate through them. For each handler, the
runtime checks if the signaled condition is of the type (or a subtype of the type) the handler was registered for. If a match is
found, the handler function is invoked. If the handler returns normally (declines), the search continues with the next applicable
handler.
Dynamic Tags
The handler-bind implementation itself relies on the dynamic state of the thread-local activeHandlers
list. However, when used in conjunction with handler-case, unique dynamic tags (typically fresh ListCell
objects) are generated. These tags are used as the "target" for the throw performed by the handler, ensuring that the
control flow returns exactly to the correct handler-case frame and doesn't conflict with other active handler or catch
frames.
handler-case as an Extension of handler-bind
In CLRHack, handler-case is not a primitive but a macro that expands into a combination of block,
catch, and handler-bind. It extends handler-bind by providing a mechanism to automatically
exit the signaling context and execute a specific branch of code based on the condition caught.
The implementation details of the expansion are as follows:
Exit Block: The entire form is wrapped in a block with a unique exit tag to allow the normal
path to return immediately upon completion of the protected expression.
Dynamic Setup: A unique dynamic tag is created for the catch frame. Local variables are
established to store the captured condition and a unique ID identifying which clause was triggered.
The Binding: A handler-bind is generated where each handler function is a closure that, when
called:
Saves the signaled condition into the local condition-var.
Sets the id-var to a unique GENSYM representing that specific clause.
Performs a throw to the dynamic tag.
The Catch and Dispatch: A catch block surrounds the protected expression. If a handler performs
the throw, the catch returns, and a cond statement (the dispatcher) checks the
id-var. It then executes the body of the matching handler-case clause with the condition variable bound
to the clause's parameter.
In the CLRHack compiler, restart-bind is a primitive form that manages the dynamic lifecycle of Common Lisp
restarts by manipulating a thread-local stack of active restart objects.
Handling of restart-bind
When the compiler encounters a restart-bind form, it generates CIL code that performs the following steps:
Capture Previous State: It calls Lisp.RestartControl::GetActiveRestarts() to retrieve the
current list of active restarts and stores it in a frame-local variable.
Construct New List: For each binding, it evaluates the restart name, handler function, and optional keyword
arguments (:report-function, :interactive-function, :test-function). It then instantiates a
new [LispBase]Lisp.Restart object and conses it onto the existing list.
Install New State: It calls Lisp.RestartControl::SetActiveRestarts(new_list) to update the
dynamic environment.
Protected Execution: The body of the restart-bind is wrapped in a CIL .try
block.
Restoration: A finally block is emitted that restores the previously saved restart list using
SetActiveRestarts, ensuring that restarts are properly uninstalled even if the body performs a non-local exit.
Lexical Non-Local Exits
The CLRHack compiler supports lexical non-local exits (e.g., return-from or go) through an
exception-based mechanism. During the analyze-environment pass, the compiler identifies if a return-from
target block is "non-local" (i.e., the return occurs within a nested closure). If so:
The target block is wrapped in a try/catch for
[LispBase]Lisp.BlockExitException.
The block is assigned a unique string ID.
The return-from form is compiled into a throw of a BlockExitException, which
carries the target ID, the return value, and a captured array of multiple return values (retrieved via
Lisp.Values::CaptureValues()).
The catch handler verifies the target ID. If it matches, it restores any captured multiple values and resumes
normal execution; otherwise, it rethrows the exception.
Restart Search
The search for an applicable restart is handled at runtime by Lisp.RestartControl::FindRestart. It performs a
linear search through the current thread's activeRestarts list (stored in a [ThreadStatic] field). It can
accept either a symbol name or a Restart object itself. If a name is provided, the search respects shadowing,
returning the innermost (most recently bound) restart with that name.
Dynamic Tags
Dynamic tags are required for the catch and throw forms used in non-local control flow. In CLRHack, a
dynamic tag is simply a fresh object (typically a ListCell or a new System.Object) used as a unique
token. This ensures that a throw only matches the specific catch frame it was intended for, avoiding
collisions between different invocations of the same function or different restart-case blocks.
restart-case as an Extension of restart-bind
In CLRHack, restart-case is implemented as a macro that expands into a combination of block,
catch, and restart-bind. It extends the basic binding functionality by providing a built-in mechanism to
jump back to the site of the restart-case when a restart is invoked.
The implementation details are as follows:
Exit Block: The entire expansion is wrapped in a (block exit_tag ...) to allow normal
completion of the expression.
Dynamic Tag: A unique dynamic tag is created (e.g., (let ((tag (list nil))) ...)).
Catch Frame: A (catch tag ...) is established around the restart-bind and the
expression.
Binding: The restart-bind creates restarts whose handler functions are closures. When invoked,
these closures capture their arguments into local variables, set a unique clause ID, and then throw to the dynamic
tag.
Dispatch: When the throw is caught, the restart-case body executes a
cond or case statement. This dispatcher checks the clause ID set by the handler and executes the
corresponding forms provided in the restart-case clause, eventually returning the result from the
exit_tag block.
The CLRHack compiler maps Lisp unwind-protect semantics directly onto the Structured Exception Handling
(SEH) infrastructure of the .NET Common Language Runtime (CLR). Specifically, it utilizes the try...finally
construct provided by the Common Intermediate Language (CIL).
Lisp semantics require that the cleanup forms in an unwind-protect block be executed regardless of how control
leaves the protected form—whether via normal return, a non-local throw, or a lexical exit like
return-from. The CLR guarantees that a finally block will execute during stack unwinding, which is
exactly the hook required for Lisp. The implementation details are as follows:
Protected Form: The compiler generates the code for the protected form inside a CIL try
block. Upon successful completion, the primary return value is stored in a local variable, and a leave instruction is
used to exit the try block, which automatically triggers the transition to the finally block.
Side-Channel Preservation: A unique challenge in Lisp is that unwind-protect must return the
values of the protected form, but cleanup forms may themselves perform operations that alter the Multiple Return Value (MRV)
side-channel. CLRHack exploits method-local variables to save the ReturnCount and the contents of Value1
through Value63 at the very beginning of the finally block and restore them at the very end.
Unwinding: If a throw or other exception occurs within the try block, the CLR
stack walker identifies the finally block and executes it before propagating the exception further. This ensures
Lisp's "cleanup guarantee" is maintained even during catastrophic or non-local control transfers.
Handling of catch and throw
Lisp's catch and throw are implemented as a Dynamic Non-Local Exit system built on
top of .NET's exception propagation mechanism. While CLR exceptions are typically filtered by type, Lisp requires filtering by a
dynamic "tag" object (compared via eq).
The throw Mechanism
When a (throw tag value) is evaluated, CLRHack does not simply perform a jump. Instead, it performs the following
steps:
Evaluates the tag and the primary value.
Captures the current state of the MRV side-channel into an object[].
Instantiates a specialized exception class: [LispBase]Lisp.CatchThrowException. This object acts as a carrier
for the tag, the primary value, and the captured MRV array.
Executes the CIL throw instruction. This initiates the CLR's SEH stack walk.
The catch Mechanism
The (catch tag body) form is compiled into a try...catch block where the catch handler specifically
targets CatchThrowException:
Tag Setup: The catch tag is evaluated and stored in a method-local variable.
Body Execution: The body forms are executed within a try block.
The Catch Handler: When a CatchThrowException is intercepted, the handler performs a "Dynamic
Filter":
It extracts the tag from the exception object and compares it to the local catch tag using
System.Object.Equals (simulating Lisp's eq for reference types).
Match: If the tags match, the handler "claims" the exception. It extracts the primary value and
the MRV array from the exception, restores them to the thread-local side-channel, and resumes normal execution after the
catch block.
Mismatch: If the tags do not match, the handler executes the CIL rethrow instruction.
This allows the exception to continue up the stack to find a matching catch tag in a higher frame.
Exploiting SEH for Lisp Semantics
CLRHack exploits the CLR's SEH in three fundamental ways to bridge the gap between .NET and Lisp:
Automatic Stack Unwinding: By using throw and try...catch, the compiler
delegates the complex task of cleaning up stack frames, registers, and intermediate states to the highly optimized .NET
runtime.
Guaranteed Cleanup: The finally block is the "silicon reality" of Lisp's
unwind-protect. The CLR ensures it runs even if an exception is re-thrown multiple times or if a thread is being
terminated.
Payload-Heavy Exceptions: Unlike standard .NET exceptions which often carry only metadata,
CatchThrowException is exploited as a transport mechanism. It carries the entire "return state" of a Lisp expression
(primary value + MRV side-channel) across an arbitrary number of stack frames, allowing a throw to behave exactly like
a multi-valued return to a dynamic point.
Common Lisp is renowned for its excellent object system CLOS. Its implementation
is often accompanied by the Metaobject Protocol that, while it is not part of
the standard, allows programmers to customize the system underpinnings in
numerous interesting ways. This level of customization doesn't come without a
cost – some CLOS code paths will be slower compared to open-coding equivalent
solutions without the use of standard objects.
The purpose of this blog post is to draw an intuition of differences between
structure objects and standard objects when it comes to accessing their slots.
From now on I'm going to refer to structure objects as structures, and standard
objects as instances.
We could imagine a structure is represented in memory as a tuple (CLASS SLOTS),
while an instance is represented as a tuple (CLASS STAMP SLOTS). Modifying the
structure class has undefined behavior, while the instance's class may
change. This is why the instance needs to track whether it is up-to-date or
obsolete. In our simple scheme that information is represented by a stamp that
represents the class generation.
Tracking whether the instance is obsolete is important, because the memory
layout of slots may change - they may be deleted, added, or moved to different
positions. This is convenient for long-running programs without downtime, for
incremental development and for image-based workflows - the program may be
modified at any time to account for changing requirements, without recompiling
it from scratch.
But this doesn't come without a downside. The implementation may conformingly
assume that structure accessors won't ever change and therefore they can be
inlined. In this case, structure access is a simple memory reference.
On the other hand, this can't be assumed for objects, as they must be checked
for obsolescence (at the very least), and because readers are more generic
functions - another level of flexibility. Inlining generic functions is hard
because new methods may be added at runtime and the effective method can change.
Moreover, there may be different classes that have same reader names, so we need
to include a piece of code that uses the correct class layout for an instance.
This is why calling instance readers involves:
calling a function (can't be inlined)
finding the memory layout (dispatch)
verifying whether the instance is up-to-date
That is exemplified by the following pseudocode that ignores other generic
function intrinsics. Depending on the implementation of generic functions, the
test for obsolete instances may be evaded when instances are not obsolete.
(declaim (notinline instance-reader-a))
(define-reader-function instance-reader-a (object)
(unless (%up-to-date-p object)
;; Among other things updates indexes for memory accesses.
;; This is a slow path.
(%recompile-reader-function #'instance-reader-a)
(return-from instance-reader-a (instance-reader-a object)))
(typecase object
(standard-class-a (svref (%slots object) 3))
(standard-class-b (svref (%slots object) 4))
(custom-class-c (slot-value object 'a))
(custom-class-d (slot-value object 'a))
(otherwise (no-applicable-method #'instance-reader-a object))))
All this is assuming that we're dealing with standard readers. Using the
metaobject protocol it is possible to store slot values anywhere - most notably,
not in a vector bundled with the instance - or to add additional preprocessing.
I'm not going to touch on MOP much here; this is just to signify that standard readers
for standard classes may directly access the slot vector.
At minimum, assuming a single reader and a clever dispatch algorithm:
In other words, comparing structure access with instance readers is comparing
apples to oranges, because the former is a memory access, while the latter is a
function call.
SLOT-VALUE will be even slower, because this function is a trampoline to a more
involved SLOT-VALUE-USING-CLASS, and to do that we need to:
read the object class
find the slot definition in the class
invoke a generic function SLOT-VALUE-USING-CLASS
The generic function SLOT-VALUE-USING-CLASS may be similar to the reader defined
above, with the caveat that it has more arguments to dispatch on (so the
dispatch procedure may be more involved). In any case, it is at least as slow as
the optimal reader defined above (a single reader for the standard class).
Tim Bradshaw recently made a blog post that claims that instance slot access is
around 38x slower than structure access, but he compares inlined memory access
to generic function dispatch. A fair comparison would use the operator
STANDARD-INSTANCE-ACCESS.
The metaobject protocol defines MOP:STANDARD-INSTANCE-ACCESS, an optimized way
to access instance slots that does not incur the overhead associated with
dispatching generic functions. This function may be inlined and is similar to
structure object accessors. A possible definition would look like this:
The argument LOCATION is technically an opaque object, but for illustration
purposes we assume that it is an index (it usually is!). Its value may be read
using the function SLOT-DEFINITION-LOCATION.
Let's dig into benchmarks! We will measure access time to slots in equivalent
structure and instance, each containing ten untyped slots initialized with fixnums.
instance : reader, SLOT-VALUE and MOP:STANDARD-INSTANCE-ACCESS
Moreover, to put some pressure on a hypothesized method cache, we will randomize
access to slots. The macro expand-body generates consecutive access forms:
(defmacro expand-body (type n-access)
(flet ((random-a () (nth (random 10) '(a-a a-b a-c a-d a-e a-f a-g a-h a-i a-j)))
(random-b () (nth (random 10) '(b-a b-b b-c b-d b-e b-f b-g b-h b-i b-j)))
(random-s () (nth (random 10) '(a b c d e f g h i j)))
(random-l () (nth (random 10) *locations*)))
(ecase type
(:reader
`(progn
,@(loop repeat n-access
for read = `(,(random-a) object)
collect `(incf count (the fixnum ,read)))))
(:slot-value
`(progn
,@(loop repeat n-access
for read = `(slot-value object ',(random-s))
collect `(incf count (the fixnum ,read)))))
(:instance-access
`(progn
,@(loop repeat n-access
for read = #+lispworks `(mop:fast-standard-instance-access object ',(random-l))
#-lispworks `(mop:standard-instance-access object ',(random-l))
collect `(incf count (the fixnum ,read)))))
(:structure-access
`(progn
,@(loop repeat n-access
for read = `(,(random-b) object)
collect `(incf count (the fixnum ,read))))))))
Now our "benchmark tool" and the tests. It is a simple measurement that compares
internal real times before and after the computation.
I've run these tests on four implementations. This table presents ratios of the
access pattern compared to the best result. Absolute timings are not included.
Implementation
reader / best
svalue / best
access / best
struct / best
CCL 1.12.2
17
12
2
1
ECL 26.5.5
616
719
1
175
LispWorks 8.1.2
22
79
1
1
SBCL 2.4.2
10
9
1
1
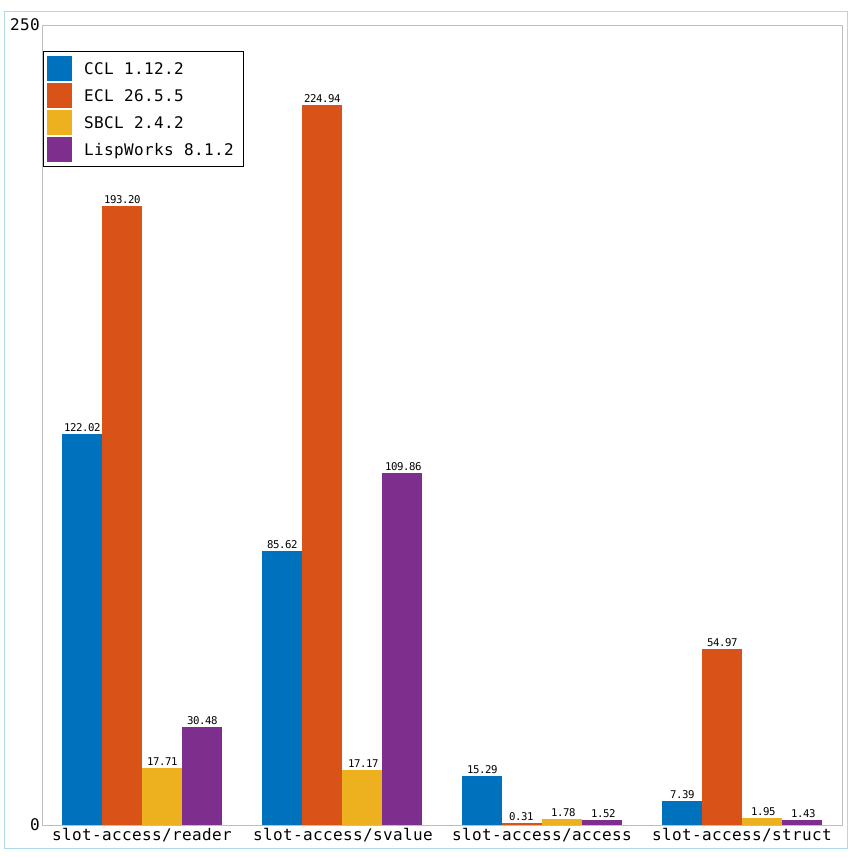
Edit: I've been asked a few times for a comparison between implementations,
so I'm also including a bar chart comparing absolute timings between them:
Y-axis is in seconds and each bar represents 2^26 x 100 slot accesses in
randomized order.
Conclusions:
Accessing slots using generic functions is indeed slower than a single memory
access. This is because we can't inline these functions, and we must take care
of many possibilities - most notably dispatching arguments of different classes
and redefinitions of both the instance class and the reader generic function.
All this cost buys us extensibility and runtime flexibility of the program.
Readers, under certain circumstances, can be better optimized than SLOT-VALUE,
because they don't have to go through another function and access class slot
definition. CCL and SBCL don't exploit this optimization opportunity.
Instance memory access and structure memory access times are roughly the same on
SBCL and LispWorks, while instance access is two times slower on CCL.
ECL does a peculiar thing where structure readers are not inlined for some
reason. That needs investigating, but hey, instance access is 175x faster ;-)!
Instance access is also abnormally fast compared to other imlpementations and
that also begs for investigation.
Notes:
To avoid external dependencies, I've defined a very basic time measurement and
used MOP operators directly defined by a few hand-picked implementations. For
more complete solutions look into "trivial-benchmark" by Yukari Hafner and
"closer-mop" by Pascal Costanza.
Lispworks' CLOS::STANDARD-INSTANCE-ACCESS does not conform to MOP
specification and errors when supplied with the slot location (it expects the
slot name). That severely impacts the performance of instance access. The
correct function to call is, for some reason,
CLOS::FAST-STANDARD-INSTANCE-ACCESS.
ECL performance is poor in comparison, but I have good news! I'm implementing
Fast Generic Function Dispatch algorithm and it will get better.
Somewhat a point of interest, but some implementations specialize
slot-value-using-class and other CLOS protocols to structure classes too.
Plots were generated with Polyclot, work-in-progress McCLIM implementation of
Grammar for Graphics.
I'd like to thank modula t. for reviewing this post and suggesting
improvements.
The CLRHack compiler implements Multiple Return Values (MRV) by extending the single-value limitation of the .NET Common
Intermediate Language (CIL) stack through a thread-local side-channel. This allows Lisp forms to communicate
multiple values (up to 64) across function boundaries.
1. The Side-Channel Storage
Because a CIL method can only return a single object on the stack, CLRHack utilizes a static class
[LispBase]Lisp.Values. This class contains [ThreadStatic] fields that act as a secondary communication
channel:
Primary Value: Always resides on the CIL evaluation stack.
ReturnCount: An int32 field indicating the total number of values returned
(including the primary one).
Value1 through Value63: Object fields that store the second through sixty-fourth
return values.
2. Producing Multiple Values (The Staging Logic)
To prevent corruption during evaluation, the values form uses a Stage-and-Commit strategy. This is
necessary because the side-channel is global to the thread; if a sub-expression inside a values form itself returns
multiple values, it would overwrite the global fields before the outer values form is finished.
The compilation process for (values form1 form2 ... formN) follows these steps:
Evaluation: Each form is evaluated in order.
Local Staging: The result of form1 is kept on the stack. The results of form2
through formN are immediately stored into method-local variables (temporaries). This ensures that if
form3 calls a function that returns multiple values, the result of form2 is safely tucked away in a local
variable and cannot be overwritten.
Commitment: After all forms are evaluated, the compiler generates code to move the values from the local
temporaries into the global Value1...ValueN fields.
Finalization: The ReturnCount is set to N.
3. Preservation across Control Flow
Certain Lisp constructs must evaluate sub-forms without allowing those sub-forms to interfere with the return values of the
primary form. This is handled by a Save-Restore pattern.
Multiple-Value-Prog1
The multiple-value-prog1 form evaluates its first form, then saves the entire side-channel state (the primary
value, the ReturnCount, and all ValueN fields) into local variables. It then evaluates the subsequent
forms. After they finish, it restores the side-channel state from its locals, ensuring the values of the first form are what the
caller receives.
Unwind-Protect
In unwind-protect, the protected form is evaluated and its primary result is stored in a local variable. Crucially,
the finally block (cleanup) must not destroy the side-channel state produced by the protected form. The compiler
generates code at the start of the finally block to save ReturnCount and Value1...63 into
locals. Once the cleanup forms complete, the state is restored from these locals before the method returns.
4. Nested Multiple Values (The Re-entrancy Problem)
The fundamental problem with a global side-channel is re-entrancy. If the compiler were to store form2 directly
into the global Value1 field, and then form3 involved a function call like (some-func), that
function might execute its own (values ...) logic. This would overwrite the global Value1 that was just
set for the outer form.
By enforcing the use of method-local temporaries during the production of values, CLRHack ensures that the
global side-channel is only updated at the last possible moment ("atomically" relative to the Lisp expression), effectively
shielding the return values from being corrupted by nested evaluations.
I’ve been interested in how slow CLOS slot access is in Common Lisp. Here’s how I measured it.
I wanted to compare the cost of access to fields of various objects in Common Lisp. In particular I wanted to get a feel for the difference between a slot in a class defined with defclass, so an instance of a subclass of standard-object, and a field in a class defined with defstruct, so an instance of a subclass of structure-object.
A naïve model of the access cost
I measured forms like
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (slot-value a 'a)))
(incf s (the fixnum (slot-value a 'b)))
...))
For \(N\) iterations you might think the time \(T\) should be
\[T = N(c_l + n(c_i + c_s)) + c_c\]
where \(c_l\) is the per-step loop overhead, \(n\) is the number of slots, \(c_i\) is the time to increment a variable, \(c_s\) is the slot read cost (the thing we want), and \(c_c\) is the overhead of calling the function to do all this. \(N\gtrapprox 10^9\), so it’s safe to treat \(c_c\) as zero. This is linear in \(n\), and \(T\) is a thing we can measure, so we can differentiate and get an expression for \(c_s\) which is what we want.
\[c_s = \frac{1}{N}\frac{dT}{dn} - c_i\]
In fact, everything works in terms of the per-step time \(t\doteq T/N\) as \(N\) varies for different classes and numbers of slots to keep the runtimes reasonable, and then \(c_s = dt/dn - c_i\).
A better model
Well, this turns out to be wrong. In particular if you estimate \(c_i\) (see below on how I did this) and use it in the above expression you will end up calculating values of \(c_s\) for structures which are either absurdly tiny (\(\sim 10^{–11}\)s for a machine with a cycle time \(\sim 10^{-9}\)s) or even negative. The reason is pretty obviously that the increment and the access are largely overlapped.
So in what follows I simply treat \(c_i\) as zero. This may overestimate \(c_s\) somewhat. But a result of that overestimation is that the factor by which slot access is slower than structure field access will be underestimated, which will make CLOS seem faster than it is, since if \(a \gt b \gt c \gt 0\) then \((a - c)/(b - c) \gt a/b\). That’s good, because what I’m trying to demonstrate is that it’s really slow, so an underestimation is safe.
The new model expression for \(c_s\) is then just \(c_s = dt/dn\).
What I did
I measured slot access time in the same way for a class with 10 slots, measuring 2, 4, 6, 8 and 10 slots, and did the same thing for a structure with 10 fields.
Because the access times and numbers of accesses per step vary widely I adjusted the number of iterations to keep the run-times sane: more than 10 seconds per test but ideally less than 60.
Each measurement was repeated 4 times.
I then fitted a linear function to the data for each class (least-squares fit), and used its gradient and the estimated variable-increment cost to estimate \(c_s\) for each type.
All the measurements were done on an M1 MacBook Air, using caffeinate to prevent it sleeping. I measured LispWorks 8.1.2 and SBCL 2.6.4. Total run times were somewhat over an hour for each implementation.
Results
SBCL slot access data and best fit
LispWorks slot access data and best fit
SBCL structure field access data and best fit
LispWorks structure field access data and best fit
From these you can see that the results are consistent between runs and the best fit is pretty good.
The per-slot cost is then the slope of the best fit curve, or perhaps slightly less.
Structure field access cost estimate
SBCL: \(c_s \approx 3.2\times 10^{-10}\)s.
LispWorks: \(c_s \approx 3.1\times 10^{-10}\)s.
Note that these are both almost certainly a single cycle up to rounding.
The ratios between these two values for each implementation are then about 38 for SBCL and about 32 for LispWorks: this is how much slower CLOS slot access is than structure field access. In fact it is probably an underestimate of how much slower it is.
This is not because multiple inheritance is inherently slow: it’s because the design of CLOS, especially if you want to take the AMOP MOP seriously, implies crappy performance.
Can this be fixed? Yes, I think so, with well-defined tradeoffs. Will it be? Up to implementors. So, probably not, sadly.
Notes
To get an estimate of the time to increment a variable, \(c_i\), first measure a large number of iterations of an empty loop and then a loop which increments a variable 100 times for each step. Both of the implementations I measured do not optimize empty loops away, intentionally I think. This estimate is now not used (see above), but if it’s not about a clock cycle (about \(3.3\times 10^{-10}\)s on M1) then probably something is wrong.
Code
This is the CL code I used.
;;;; Some slot-value benchmarks
;;;
;;; None of this code is general-purpose.
;;;
(in-package :cl-user)
(define-condition too-short (simple-error)
((seconds :initform 0 :initarg :seconds :reader too-short-seconds)))
(defmacro noting-too-short (&body forms)
`(handler-bind ((too-short (lambda (e)
(format *debug-io* "~&Too short: ~,2Fs when minimum was ~Ds~%"
(too-short-seconds e)
*minimum-seconds*)
(continue e))))
,@forms))
(defvar *minimum-seconds* 10) ;how long it must run for
(defmacro ticks (&body forms)
`(let ((start (get-internal-real-time))
(end (progn
,@forms
(get-internal-real-time))))
(let* ((elapsed-ticks (- end start))
(elapsed-seconds (/ elapsed-ticks internal-time-units-per-second)))
(when (< elapsed-seconds *minimum-seconds*)
(cerror "just return ~D (~,2F seconds)"
(make-condition
'too-short
:format-control "~D ticks (~,2F seconds) is not long enough"
:format-arguments (list elapsed-ticks (float elapsed-seconds))
:seconds (float elapsed-seconds))
elapsed-ticks (float elapsed-seconds)))
elapsed-ticks)))
(defun seconds (ticks &optional (divider 1))
(/ ticks internal-time-units-per-second divider))
(defun note (control &rest args)
(format *debug-io* "~&[~?]~%" control args)
(force-output *debug-io*))
(defmacro noting ((&rest notes) &body forms)
;; Single value only, but this is all we need
`(progn
(format *debug-io* "~&[~@{~A~^ ~}" ,@notes)
(force-output *debug-io*)
(let ((r (progn ,@forms)))
(format *debug-io* " -> ~A]~%" r)
(force-output *debug-io*)
r)))
(defun inc-n (n incs)
(declare (type fixnum n incs)
(optimize speed (safety 0)))
(case incs
(0
(dotimes (i n 0)))
(100
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s)
(incf s))))
(otherwise
(error "what even is this"))))
(defun estimate-increment-time (&key
(exponent 11)
&aux
(n (round (expt 10 exponent)))
(n/100 (round (expt 10 (- exponent 2)))))
(declare (type fixnum n n/100))
(/ (- (seconds (noting (100 n/100) (ticks (inc-n n/100 100))) n/100)
(seconds (noting (0 n) (ticks (inc-n n 0))) n))
100))
(defclass a ()
((a :initform 0 :reader a-a)
(b :initform 0 :reader a-b)
(c :initform 0 :reader a-c)
(d :initform 0 :reader a-d)
(e :initform 0 :reader a-e)
(f :initform 0 :reader a-f)
(g :initform 0 :reader a-g)
(h :initform 0 :reader a-h)
(i :initform 0 :reader a-i)
(j :initform 0 :reader a-j)))
(defstruct b
(a 0)
(b 0)
(c 0)
(d 0)
(e 0)
(f 0)
(g 0)
(h 0)
(i 0)
(j 0))
(defgeneric svn (o n count &key)
(declare (optimize speed)))
(defmethod svn ((a a) n count &key (reader nil))
(declare (type fixnum n count)
(optimize speed (safety 0)))
(if reader
(case count
(2
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (a-a a)))
(incf s (the fixnum (a-b a))))))
(4
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (a-a a)))
(incf s (the fixnum (a-b a)))
(incf s (the fixnum (a-c a)))
(incf s (the fixnum (a-d a))))))
(6
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (a-a a)))
(incf s (the fixnum (a-b a)))
(incf s (the fixnum (a-c a)))
(incf s (the fixnum (a-d a)))
(incf s (the fixnum (a-e a)))
(incf s (the fixnum (a-f a))))))
(8
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (a-a a)))
(incf s (the fixnum (a-b a)))
(incf s (the fixnum (a-c a)))
(incf s (the fixnum (a-d a)))
(incf s (the fixnum (a-e a)))
(incf s (the fixnum (a-f a)))
(incf s (the fixnum (a-g a)))
(incf s (the fixnum (a-h a))))))
(10
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (a-a a)))
(incf s (the fixnum (a-b a)))
(incf s (the fixnum (a-c a)))
(incf s (the fixnum (a-d a)))
(incf s (the fixnum (a-e a)))
(incf s (the fixnum (a-f a)))
(incf s (the fixnum (a-g a)))
(incf s (the fixnum (a-h a)))
(incf s (the fixnum (a-i a)))
(incf s (the fixnum (a-j a))))))
(otherwise
(error "what even is this")))
(case count
(2
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (slot-value a 'a)))
(incf s (the fixnum (slot-value a 'b))))))
(4
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (slot-value a 'a)))
(incf s (the fixnum (slot-value a 'b)))
(incf s (the fixnum (slot-value a 'c)))
(incf s (the fixnum (slot-value a 'd))))))
(6
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (slot-value a 'a)))
(incf s (the fixnum (slot-value a 'b)))
(incf s (the fixnum (slot-value a 'c)))
(incf s (the fixnum (slot-value a 'd)))
(incf s (the fixnum (slot-value a 'e)))
(incf s (the fixnum (slot-value a 'f))))))
(8
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (slot-value a 'a)))
(incf s (the fixnum (slot-value a 'b)))
(incf s (the fixnum (slot-value a 'c)))
(incf s (the fixnum (slot-value a 'd)))
(incf s (the fixnum (slot-value a 'e)))
(incf s (the fixnum (slot-value a 'f)))
(incf s (the fixnum (slot-value a 'g)))
(incf s (the fixnum (slot-value a 'h))))))
(10
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (slot-value a 'a)))
(incf s (the fixnum (slot-value a 'b)))
(incf s (the fixnum (slot-value a 'c)))
(incf s (the fixnum (slot-value a 'd)))
(incf s (the fixnum (slot-value a 'e)))
(incf s (the fixnum (slot-value a 'f)))
(incf s (the fixnum (slot-value a 'g)))
(incf s (the fixnum (slot-value a 'h)))
(incf s (the fixnum (slot-value a 'i)))
(incf s (the fixnum (slot-value a 'j))))))
(otherwise
(error "what even is this")))))
(defmethod svn ((b b) n count &key)
(declare (type fixnum n)
(optimize speed (safety 0)))
(case count
(2
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (b-a b)))
(incf s (the fixnum (b-b b))))))
(4
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (b-a b)))
(incf s (the fixnum (b-b b)))
(incf s (the fixnum (b-c b)))
(incf s (the fixnum (b-d b))))))
(6
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (b-a b)))
(incf s (the fixnum (b-b b)))
(incf s (the fixnum (b-c b)))
(incf s (the fixnum (b-d b)))
(incf s (the fixnum (b-e b)))
(incf s (the fixnum (b-f b))))))
(8
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (b-a b)))
(incf s (the fixnum (b-b b)))
(incf s (the fixnum (b-c b)))
(incf s (the fixnum (b-d b)))
(incf s (the fixnum (b-e b)))
(incf s (the fixnum (b-f b)))
(incf s (the fixnum (b-g b)))
(incf s (the fixnum (b-h b))))))
(10
(let ((s 0))
(declare (type fixnum s))
(dotimes (i n s)
(incf s (the fixnum (b-a b)))
(incf s (the fixnum (b-b b)))
(incf s (the fixnum (b-c b)))
(incf s (the fixnum (b-d b)))
(incf s (the fixnum (b-e b)))
(incf s (the fixnum (b-f b)))
(incf s (the fixnum (b-g b)))
(incf s (the fixnum (b-h b)))
(incf s (the fixnum (b-i b)))
(incf s (the fixnum (b-j b))))))
(otherwise
(error "what even is this"))))
(defun measure-thing (thing &key
(exponent 11)
(specs
'((2 -0.2)
(4 -0.4)
(6 -0.6)
(8 -0.8)
(10 -1)))
(sleep 0)
&aux (cn (class-name (class-of thing))))
(mapcar (lambda (spec)
(destructuring-bind (count delta &rest kws &key) spec
(let ((iterations (round (expt 10 (+ exponent delta)))))
(let ((per-step (float
(seconds (noting (cn count iterations)
(ticks (apply #'svn thing
iterations count kws)))
iterations))))
(note "~S ~D elapsed ~Ds per-step ~Ds"
cn count (* per-step iterations) per-step)
(when (> sleep 0)
(noting ("sleep" sleep)
(sleep sleep)))
(list cn count per-step)))))
specs))
(defun measure-things (&key
(things-and-exponents `((,(make-b) 11)
(,(make-instance 'a) 10)))
(log-file "thing-times.ldat")
(tries 4)
(sleep 5))
;; Dump measurements to a log file
(with-standard-io-syntax
(with-open-file (log log-file :direction :output
:if-exists :supersede)
(noting-too-short
(let ((increment-time (float (estimate-increment-time))))
(note "increment time ~Ds" increment-time)
(pprint increment-time log)
(force-output log))
(dolist (thing-and-exponent things-and-exponents)
(destructuring-bind (thing exponent) thing-and-exponent
(note "~S exponent ~D"
(class-name (class-of thing))
exponent)
(dotimes (try tries)
(pprint
(measure-thing thing
:exponent exponent
:sleep sleep)
log)
(force-output log)))))))
log-file)
This is the Racket code which plotted the data and computed the fit & cost.
I decided to make proper tail recursion a fundamental requirement in CLRHack. This prevents stack overflow errors during standard recursive patterns and ensures the runtime remains stable
regardless of recursion depth. Technically, Common Lisp isn't required to be tail recursive, but I want mine to be.
1. Tail Position Identification
The compiler performs a structural analysis of the Abstract Syntax Tree (AST) to identify "tail positions." An expression is in
a tail position if its value is the final result of the function, meaning no further work remains to be done in the current frame
after the call returns. The generate-step2 walker propagates a tail-p flag through the following
logic:
Functions/Lambdas: The final expression in the body is in the tail position.
Conditionals (IF): Both the "then" and "else" branches are in the tail position.
Sequences (PROGN/LET): Only the very last form in the sequence is in the tail position.
Blocks: The last form of a BLOCK is in the tail position, provided the block is not the
target of a RETURN-FROM.
2. CIL Instruction Emission
To implement proper tail-call semantics, the compiler utilizes the native tail. prefix in the Common Intermediate
Language (CIL). When a function call is detected in a tail position, the compiler applies the following mandatory
transformation:
The Prefix: It prepends the tail. opcode to the call or callvirt
instruction.
The Return: It immediately follows the call with a ret (return) instruction.
The tail. prefix instructs the .NET Just-In-Time (JIT) compiler to discard the current method's stack frame before
jumping to the target function. This ensures that the call consumes zero additional stack space, turning the recursive call into a
semantic jump.
3. Safety and Context Constraints
The implementation of tail-calls is subject to specific safety rules imposed by the Common Language Runtime (CLR) to maintain
execution integrity:
Protected Regions: The CLR prohibits tail. calls inside try, catch,
or finally blocks. Because Lisp constructs such as unwind-protect and handler-case rely on
these CIL features, tail-call elimination is suspended within these specific scopes to ensure cleanup handlers and error recovery
mechanisms function correctly.
Frame Cleanup: The compiler ensures that all local resources are in a valid state before the
tail. prefix is issued, allowing the CLR to safely deallocate the current frame.
Example CIL Output
Consider a recursive counter that must be able to run indefinitely:
(defun count-down (n)
(if (= n 0)
"Done"
(count-down (- n 1))))
The compiled CIL for the recursive branch is transformed to ensure stack neutrality:
; ... code to calculate (- n 1) ...
tail.
call object Program::'COUNT-DOWN'(object)
ret
By strictly enforcing this pattern, CLRHack guarantees that recursive programs can execute with constant stack space, fulfilling
my core requirement of tail recursion.
HEΛP is the Common Lispcode documentation tool I started writing many years ago.
Apart from a little necessary Javascript and CSS, HEΛP
is a full Common Lisp program, geared towards producing static documentation sites for CL code.
I finally got around to modernize it and it is now ready for testing.
Evolution from (X)HTML to HTML5
The original HEΛP release was producing only (X)HTML output, moreover
based on FRAMESETs.
Alas, when the first HEΛP release was made, FRAMESETs were falling out of fashion,
and they were eventually deprecated with the advent of HTML5. An "upgrade" to HTML5
became then a necessity.
After a very long process, I finally finished the HTML5 port, plus some bells and whistles. All in all,
the implementation uses <div ... > sections plus CSS to lay out the display, as I understand
it is the proper coding fashion nowadays. The port uses the
W3.CSS styles, which facilitated a number of
choices. The result is rather pleasing, as far as I am concerned.
Example: Producing the HEΛP documentation
The HEΛP documentation (a form of it) is produced with the following command
(hlp is one of the package nicknames):
(hlp:document #P"./" ; Just a "top directory"...
:documentation-title "HEΛP"
:format :html5
:exclude-directories
(list "doc/"
"js/"
"css/"
".git/"
"tests/"
"tmp/"
"tools/"
)
:exclude-files ; I run this from LW.
(list "impl-dependent/ccl.lisp"
"impl-dependent/sbcl.lisp"
"utilities/document-helambdap.lisp"
"utilities/lambda-list-parsing.lisp"
)
:only-documented t
:only-exported t
)
After much printing, the resulting static web pages are deposited in docs/html5/, unless overridden.
The system also relies on some defaults which are handled by
CLAD library.
Viewing the result.
For the time being, you can find the main page of
HEΛPhere. Navigating the bar on the left
will allow you to see different bits and pieces fo the documentation. You will notice that you have different views
of the documentation: a system view and a package view. The system view gives you also a view of
the files and folders (modules) it contains.
Documentation strings are mostly left alone.
Unike for Emacs Lisp,
there is no real agreement in the CL community about how to format documentation strings (if there is, I do not agree
with it by definition - obviously). HEΛP wants to be able to document code that does not adopt any documentation
string convention, therefore it treats documentation strings pretty much as they are, only adding some text in the guise
of the Hyperspec entries.
Screenshot
Here are a couple of screenshots. Apologies for the bad resolution.
The Main View
The DIctionary View
Missing Pieces
There is one thing that is missing from HEΛP: the generation of proper crossreferencing. To do it correctly it will be
necessary to somehow make some educated guesses about the content of documentation strings or agreeing on some markup
to tag linkable items. Apart from that, at the time of this writing the doc strings are handled as enties in an has table,
and that could be improved, as more indexes may be needed.
Of course, a major rewrite may also help, but time is a tyrant.
... and remember: no Python or Ruby or Shell dependencies: pure CL (plus some Javascript, which is a functional
language after all, whose first implementation was done in CL).
CLRHack implements lexical closures by transforming dynamic Lisp environments into static CIL class structures. Since the .NET
Common Language Runtime (CLR) does not have a native concept of "nesting" functions within the lexical scope of another function's
local variables, the compiler employs Lambda Lifting and Explicit Closure Conversion.
1. Lambda Lifting
Every lambda expression (including those generated by flet and labels) is extracted from
its nesting site. The compiler generates a unique, standalone CIL class for each lambda. These classes inherit from the base
[LispBase]Lisp.Closure class.
2. The Closure Class Structure
The generated class acts as a container for both the code (the lambda body) and the environment (the captured variables). It
consists of:
Environment Fields: For every "free variable" (a variable referenced in the lambda but defined in an outer
scope), the compiler adds a public field to the class.
The Constructor: A constructor is generated that accepts the values (or references) of these free
variables and stores them in the class fields.
The Invoke Methods: The class overrides the virtual Invoke methods of the base
Closure class. The body of the Lisp lambda is compiled into these methods.
3. Environment Capture
At the point in the code where the lambda is defined, the compiler emits a newobj instruction. It
passes the current values of the required local variables into the closure's constructor. This "closes" over the variables,
creating a persistent instance of the environment that lives on the heap.
Common Lisp requires that if an outer variable is mutated (via setq), all closures capturing that variable must see
the change. To support this, CLRHack uses Indirection Cells:
If the compiler detects that a captured variable is mutated, it "boxes" that variable.
Instead of storing a raw value (like an integer) on the stack, it creates a [LispBase]Lisp.ValueCell
object.
The closure captures the reference to this ValueCell.
Both the parent function and the closure access the variable by reading from or writing to the Value field of
the cell. This ensures that all parties share the same mutable state.
5. Invocation
When a closure is invoked (e.g., via funcall), the Invoke method is called. Inside this method, the
this pointer (ldarg.0 in CIL) provides the code with access to the captured environment fields. This
allows the lifted function to behave as if it were still sitting inside its original lexical scope.
The CLRHack engine translates the dynamic, flexible argument-passing semantics of Common Lisp into the static,
strongly-typed environment of the .NET Common Language Runtime (CLR). It achieves this through a combination of
CIL method overloading, sentinel-based defaulting, and runtime list
construction.
1. The Overloading Architecture
Since CIL methods have a fixed arity (number of arguments), but Common Lisp functions support variable arguments, the
compiler generates multiple entry points for every defined function.
Public Overloads: For every function, the compiler generates a set of public static
methods (typically from 0 to 8 arguments). These serve as the "API" for both direct calls and closure invocation.
The Body Method: The actual logic of the Lisp function is compiled into a single private
static method named [FunctionName]_Body. All valid public overloads normalize their arguments and delegate
to this method.
Arity Enforcement: Overloads representing invalid argument counts (e.g., calling a 2-arg function
with 5 args) are generated to throw a Lisp.WrongNumberOfArgumentsException.
2. Parameter Type Implementation
Required Parameters
Required parameters are the simplest. They map directly to the leading object arguments in both the public
overloads and the internal body method.
Optional Parameters (&optional)
Handling &optional involves a "Sentinel Pattern":
Sentinels: If a caller uses an overload that provides fewer than the maximum number of optional
arguments, the compiler passes a special global constant: Lisp.Undefined::Value.
Late Defaulting: Inside the _Body method, the engine generates CIL code to check if
the argument is EQ to the Undefined sentinel. If the check passes, the code evaluates the Lisp default expression
and stores the result back into the parameter using starg.
Supplied-p: If the Lisp code defines a "supplied-p" variable, an extra boolean parameter is added
to the _Body method, which is set to true or false based on the presence of the
argument in the specific overload.
Rest Parameters (&rest)
Rest parameters are handled by runtime list construction:
In the public overloads, any arguments provided beyond the required/optional count are bundled into a linked list
using Lisp.List/ListCell.
The _Body method receives this list as a single object argument.
Keyword Parameters (&key)
Keyword parameters are implemented as a transformation over the &rest mechanism:
Trailing arguments are gathered into a "rest" list.
The _Body method defines local variables for every keyword parameter, initialized to their Lisp
default values.
The Keyword Loop: At the start of the function, the engine emits a loop that scans the rest list
in pairs. It uses Object.Equals to compare each key against the pre-interned keyword symbols (e.g.,
:TEST). When a match is found, the corresponding local variable is updated with the value following the key.
3. The Calling Mechanism
Direct Calls
When the compiler identifies a call to a known defun in the same assembly, it emits a direct
call to the public overload that exactly matches the number of provided arguments. This provides near-native
performance for fixed-arity calls.
Indirect Calls (Closures & Funcall)
All Lisp functions are instances of the Lisp.Closure class. This class provides virtual
Invoke methods. When a closure is created, it captures its environment and provides overrides for these
Invoke methods that jump into the appropriate Program static overloads.
4. Multiple Return Values
Note: Argument passing is only half the story; return values use a side-channel.
Because .NET methods return only one value, CLRHack uses a Thread-Static Side-Channel in the
Lisp.Values class:
The first value is returned normally as the method's return value.
Additional values are stored in [ThreadStatic] fields (Value1, Value2, ...
up to Value63).
A ReturnCount field is updated to tell the caller how many values are waiting in the buffer.
Example CIL Generation
; Lisp: (defun add-optional (x &optional (y 5)) (+ x y)); Overload for 1 arg
.method public static object 'ADD-OPTIONAL'(object x) {
ldarg 0
ldsfld object [LispBase]Lisp.Undefined::Value
tail. call object Program::'ADD-OPTIONAL_Body'(object, object)
ret
}
; The Body Method
.method private static object 'ADD-OPTIONAL_Body'(object x, object y) {
; Defaulting logic for Y
ldarg 1
ldsfld object [LispBase]Lisp.Undefined::Value
bne.un SKIP_DEFAULT
ldc.i4 5
box int32
starg 1
SKIP_DEFAULT:
; ... rest of function ...
}
The first thing to look at is the Fibonacci benchmark. The source
code is here:
(in-package "CLRHACK")
(progn
(defun fib (n)
(if (< n 2)
n
(+ (fib (- n 1))
(fib (- n 2)))))
(defun main ()
(print "Fibonacci of 10:")
(print (fib 10)))
(main))
And it compiles to this IL code: (commentary after the code)
.assembly extern mscorlib {}
.assembly extern LispBase {}
.assembly 'FibBenchmark' {}
.module 'FibBenchmark.exe'
.class public auto ansi beforefieldinit Program
extends [mscorlib]System.Object
{
.field public static class [LispBase]Lisp.Symbol 'SYM_G545'
.method public static hidebysig specialname rtspecialname void '.cctor'() cil managed
{
.maxstack 8
ldsfld class [LispBase]Lisp.Package [LispBase]Lisp.Package::CommonLisp
ldstr "T"
callvirt instance class [LispBase]Lisp.Symbol [LispBase]Lisp.Package::'Intern'(string)
stsfld class [LispBase]Lisp.Symbol Program::'SYM_G545'
ret
}
.method public static hidebysig object 'FIB'(object) cil managed
{
.maxstack 8
.locals (object TEMP_B)
ldarg 0
ldc.i4 2
box int32
stloc TEMP_B
unbox.any int32
ldloc TEMP_B
unbox.any int32
clt
brtrue TRUE543
ldnull
br END544
TRUE543:
nop
ldsfld class [LispBase]Lisp.Symbol Program::'SYM_G545'
END544:
nop
ldnull
ceq
brtrue ELSE546
ldarg 0
ret
ELSE546:
nop
ldarg 0
ldc.i4 1
box int32
stloc TEMP_B
unbox.any int32
ldloc TEMP_B
unbox.any int32
sub
box int32
call object Program::'FIB'(object)
ldarg 0
ldc.i4 2
box int32
stloc TEMP_B
unbox.any int32
ldloc TEMP_B
unbox.any int32
sub
box int32
call object Program::'FIB'(object)
stloc TEMP_B
unbox.any int32
ldloc TEMP_B
unbox.any int32
add
box int32
ret
BLOCK_END_FIB_532:
nop
ret
}
.method public static hidebysig object 'MAIN'() cil managed
{
.maxstack 8
ldstr "Fibonacci of 10:"
call void [mscorlib]System.Console::'WriteLine'(object)
ldnull
pop
ldc.i4 10
box int32
call object Program::'FIB'(object)
call void [mscorlib]System.Console::'WriteLine'(object)
ldnull
ret
BLOCK_END_MAIN_536:
nop
ret
}
.method public static hidebysig void 'Main'() cil managed
{
.entrypoint
.maxstack 8
call object Program::'MAIN'()
pop
ret
}
} // end of class Program
The first thing the fib program does is compare
argument x to the literal number 2. The
compiler pushes argument 0 on to the stack, and then the compiler
pushes a integer 2 on to the stack and boxes it.
Next, the compiler has to perform the compare. In order to do this
it must unbox both arguments. One argument is on top of the stack,
so it is put into a local TEMP_B so we can get to the other
argument. We unbox it. We then restore TEMP_B to the top of stack
and unbox it. Finally we compare the two unboxed values for less
than.
This pattern of unboxing a pair of elements from the top of stack
by way of a temporary local is repeated several places in the
compiled code as FIB rather inefficiently subtracts 1 or 2 from the
argument and makes the recursive call.
This example shows that the compiler basically treats everything as
a .NET object. It unboxes numbers at the last moment and boxes the
results as soon as they are generated. It is not efficient
code.
I was bored so I wrote a compiler. I'm lazy so I vibe coded it.
It compiles Lisp to .NET IL (the byte code that the .NET runtime
executes). The IL is then JIT compiled to machine code and
executed. You can use the dotnet runtime from Microsoft or the open
source mono runtime as the runtime for the compiled code.
The basic idea of the compiler is to map lambda expressions to .NET
classes. The lexical variables are stored as fields in the class.
The body of the lambda is compiled to a method in the class. We use
lambda lifting to flatten any nested lambdas. We use cell
conversion to handle mutable variables and we simply copy the values
of immutable variables into the lifted lambdas when they are closed
over.
Although I `vibe coded` the compiler, I leveraged my experience
with writing compilers to break down the problem into passes that
were simple enough that `vibe coding` was possible. For instance,
in order to implement lambda lifting, I first wrote a pass that
determined the free variables of each lambda. That's a pretty
simple operation that I could easily `vibe code`. In order to emit
the correct IL, I first wrote a pass that segregated the variables
into arguments, lexicals, and globals. Again, that's a simple
operation that I could easily `vibe code`.
The trickiest part was the code generator. I had decided to
implement tail recursion by using the `tail.` prefix in the IL.
This is a hint to the JIT compiler that the call is a tail call and
that it can optimize it by reusing the current stack frame.
However, the JIT compiler is a bit picky about when it will actually
perform the tail calls, and the other parts of the code generator
kept moving the tail calls around so that they were no longer in
tail position. I eventually had to add a pre-pass to the code
generator that tracked the continuations in order to ensure that
there was enough information later on to enforce tail position on
the tail calls.
It... works? It compiles a number of the Gabriel Benchmarks, and
some test programs that demonstrate lexical scoping, mutable
variables, and tail recursion. It is most definitely a Lisp
compiler, but if you look under the hood, well, be forewarned. It
isn't pretty.
The compiler itself was vibe coded. The only restriction on the
output code was that it had to implement what the input code
specified. It did not have to conform to any particular notion of
how to implement lisp features on the .NET runtime beyond the
requirement that the output was correct. Choices that are typically
made by a Lisp architect, such as how to deal with integers, the
implementation of the standard library, etc., were all left up to
the vibe coding process. I provided a couple of runtime libraries:
a cell library for implementing mutable variables, and a List
library for implementing singly linked lists. These were written in
C#. The vibe coding process was allowed to modify the C# code in
these libraries as well and it did so in a couple of places.
I started with one a simple benchmark and got it to compile and
run. From there, I added more benchmarks and each time told the
compiler to fix any errors that came up. I also added some test
programs that were not part of the benchmarks in order to test
specific features of the compiler. As I added more and more test
programs, the `vibe coding process` added more and more features to
the compiler. This ended up producing more and more complex
compiler output code.
I'm going to devote a few blog posts to this compiler, so if it
isn't up your alley, skip ahead a few posts.
Version 0.5 of DRef, the definition reifier, is now available.
It has moved to its own repository, completing its separation from
PAX, where it was originally developed.
This was a long time coming. Twelve years ago today, PAX was born.
From the start, PAX used the concept of locatives to refer to
definitions without first-class objects. For example, to generate
documentation for the *MY-VAR* variable, one could use the
VARIABLE locative as in (*MY-VAR* VARIABLE). PAX needed to be able
to tell whether such a definition exists, as well as access its
docstring and source location.
Over time, this mechanism evolved into a portable, extensible
introspection library independent of PAX. I began
separating the two projects two years ago and
named the new library, though they continued to share a repository.
I have now removed the remaining dependencies so that DRef can live
on its own.
The Lisp Machine Listener had an electric close parenthesis. When
the user typed a close parenthesis, and this was the close
parenthesis that finished the complete form at top level, the form
would be sent to the REPL right away with no need to press enter.
Here's how to get this behavior with SLY:
(defun my-sly-mrepl-electric-close-paren ()
"Insert ')' and auto-send ONLY if we are closing a top-level Lisp form."
(interactive)
(let ((state (syntax-ppss)))
(insert ")")
;; Safety checks:
;; 1. We were at depth 1 (so we are now at depth 0)
;; 2. We aren't in a string or comment
;; 3. The input actually starts with a paren (it's a form, not a sentence)
(when (and (= (car state) 1)
(not (nth 3 state))
(not (nth 4 state))
(string-match-p "^\\s-*("
(buffer-substring-no-properties (sly-mrepl--mark) (point))))
(sly-mrepl-return))))
Another cool hack is to get the REPL to do double duty as a command
line to the LLM chatbot. When you type RET in the REPL, it will
check if the input is a complete lisp form. If so, it will send the
form to the REPL as normal. If not, it will send the input to the
chatbot. Here's how to do this:
(defun my-sly-mrepl-electric-return ()
"Send to Lisp if it's a form/symbol, or wrap in (chat ...) if it's a sentence."
(interactive)
(let* ((beg (marker-position (sly-mrepl--mark)))
(end (point-max))
(input (buffer-substring-no-properties beg end))
(trimmed (string-trim input)))
(cond
;; If it's empty, just do a normal return
((string-blank-p trimmed)
(sly-mrepl-return))
;; If it starts with a paren, quote, or hash, it's definitely a Lisp form
((string-match-p "^\\s-*[(#'\"]" trimmed)
(sly-mrepl-return))
;; If it's a single word (no spaces), treat it as a symbol/form (e.g., *package*)
((not (string-match-p "\\s-" trimmed))
(sly-mrepl-return))
;; Otherwise, it's a sentence. Wrap it and fire.
(t
(delete-region beg end)
(insert (format "(chat %S)" trimmed))
(sly-mrepl-return)))))
Install as follows:
;; Apply to SLY MREPL with a safety check for the mode map
(with-eval-after-load 'sly-mrepl
(define-key sly-mrepl-mode-map (kbd "RET") 'my-sly-mrepl-electric-return)
(define-key sly-mrepl-mode-map (kbd ")") 'my-sly-mrepl-electric-close-paren))
Access to slots in CLOS instances is often very slow. It’s probably not possible for it ever to be really fast, but the AMOP MOP does provide a way of making it, at least, less slow.
How slow is it?
Here are some benchmarks for accessing fields in objects of various kinds, using SBCL. All of these tests do something equivalent to
(defclass a ()
((i :initform 0 :type fixnum)))
(defclass a/no-fixnum ()
((i :initform 0)))
(defmethod svn ((a a) n)
(declare (type fixnum n)
(optimize speed (safety 0)))
(dotimes (i n)
(incf (the fixnum (slot-value a 'i)))))
(defmethod svn ((a a/no-fixnum) n)
(declare (type fixnum n)
(optimize speed (safety 0)))
(dotimes (i n)
(incf (the fixnum (slot-value a 'i)))))
They then call svn (or equivalent) with a large value of \(n\), do that a number of times \(m\) and then divide by \(2 \times n \times m\) to get an average time per access (incf accesses the slot twice).
For SBCL 2.6.3.178-a190d9710 on ARM64 Apple M1, seconds per access:
raw fixnum increment \(1.58\times 10^{-10}\), ratio \(1.0\);
slot access with slot-value (slot type fixnum) \(1.20\times 10^{-8}\), ratio \(76\);
slot access with slot-value (no slot type) \(1.22\times 10^{-8}\), ratio \(77\);
slot access with slot-value (single slot-value-using-class method) \(1.69\times 10^{-8}\), ratio \(107\);
slot access using standard-instance-access \(1.00\times 10^{-9}\), ratio \(6.4\);
slot access, struct (slot type fixnum) \(1.57\times 10^{-10}\), ratio \(1.0\);
slot access, struct (no type) \(1.58\times 10^{-10}\), ratio \(1.0\);
slot access, cons (car) \(1.59\times 10^{-10}\), ratio \(1.0\).
These numbers vary slightly, but this gives a good picture of what is going on. In particular you can see that slot-value within a method specialised on the class is more than 70 times slower than access for a structure slot, but if you can use standard-instance-access it is only about 6 times slower: standard-instance-access speeds things up by a factor of about 10, which changes CLOS slot access performance from laughably slow to merely pretty slow.
A macro
I’ve written a macro, called with-sia-slots which is like with-slots but uses standard-instance-access. It therefore has all the constraints imposed by that, but it is significantly faster than with-slots or slot-value. It has some overhead, as it has to dynamically compute the slot locations: this is better done outside any inner loop. This means that, for instance, you probably want to write code that looks like
(with-sia-slots (x) o
(dotimes (i many)
(setf x (... x ...))))
which will mean you only pay the overhead once.
The above tests don’t use with-sia-slots, as I wrote them partly to see if something like this was worth writing. However on a current (at the time of writing) SBCL with-sia-slots is asymptotically about 10 times faster than with-slots as demonstrated by these tests.
Up to package names it should be portable to any CL with an AMOP-compatible MOP. It can be found in my implementation-specific hacks, linked from here.
In 2015 in London I attended my first European Lisp Symposium. I was 21 at the time, and while this wasn't my first time abroad on my own, it was still a pretty stressful affair. I remember it still pretty clearly to that day: meeting Robert Strandh, Zach Beane, Didier Verna, Daniel Kochmański and many other people I'd previously admired from afar through many discussions on IRC. It was an important event for me, and was the first time I'd felt like I was in a group of people I could talk with about my interests and ambitions.
Last year in 2025 I was the local chair for ELS in Zürich. It was a stressful time and I don't remember much of it other than how the stage looked, the food, and me rushing all over to get supplies and take care of other emergencies. I barely talked to anyone because I was either rushing about, stressed, or too tired.
In that time, my life has changed significantly. Over the years I took on more and more organisational roles for ELS itself: remaking the website, handling the transition to a hybrid online conference, handling the live streaming on-site, and last year being local chair.
But for other parts of the broader Lisp community I gradually changed in the opposite direction: I stopped religiously reading the #lisp/#commonlisp IRC channels. I left the Lisp Discord. I stopped replying on and ultimately altogether reading the /r/lisp subreddit. I stopped blogging about what was going on both in other places and with my own projects.
All of these changes happened over time as I found myself with less tolerance for things that annoyed me and wasted my time and energy. The endless debates about why there wasn't a new standard, the constant humm-hawwing about what """the community""" should do, why Lisp wasn't more widely used if it's so great, someone starting yet another project that was already done instead of contributing to an existing implementation, and so on and so forth.
And then I found myself thinking today: "gee, I'm not very excited to go to ELS'26, huh? Whatever happened?" I've already booked my flight and hotel, and I'll be there anyway, partly because I have to for organisational reasons. But now that I'm thinking about how I feel, I can't say for certain if I will be back next year, too. Both for financial and emotional reasons.
In recent years I've found myself more and more disconnected with male-dominated spaces in general. I don't feel at home in them. I'm already not a very social person and struggle with any kind of gathering that has more than 6 people, but a lot more so still if it's mostly men. Not necessarily because I feel like I'm in any kind of danger, but simply because I don't feel like I belong. And... you know, that's sad. Obviously me leaving won't make the situation better for the other women that do attend, but that's the dilemma with all of these situations: unless the organisation creates intentional pressure to correct the situation, it will inevitably only reinforce itself.[1]
And then there's what I can, in the nicest way, only describe as "The LLM Situation," though I will be increasingly un-nice going forward. As of early this year SBCL has happily accepted patches that are authored by or with the use of LLMs, and the maintainers have rebuffed complaints about this practise. The mailing list has also gotten its fair share of useless blather by apologists and pointless drivel dreamed up by LLMs that only wastes everyone's time, to the point where I had to just stop reading it altogether. A few maintainers of other significant projects seem to also have embraced the capitalist wasteland mass exploitation machine that disguises itself as "technology."
On the other side of things as the lead developer of Shirakumo I've decided to put out a blanket ban on all of this garbage. I do not care if LLMs work at all, or if they will ever work, or whatever. The usability of LLMs is completely irrelevant. By using them you are happily handing over the single last remaining shred of your human spirit to the capitalists to help them burn everyone else and the world with it to the ground.
I think back to the impromptu "LLM roundtable" discussion that took place at the end of ELS last year, along with the usual apologist bullshit that was spread in the ELS Signal group at the time, and some of the lightning talks that were shown. And as I think about this, I am filled with trepidation about the coming conference.
Obviously I have no idea what it will be like yet, and I have no idea what the programme will be, nor what people will be there, or what the general vibe is going to be. But nevertheless, I really hope I won't have to "crash out" as the kids say. I already lost my mind last year, seemingly being the only one that wanted to hold a firm stance against this wave of shit at the time.
So what does this all mean going forward? Well, for just now, nothing. I'll continue to be in the places I have dug out myself: mastodon, the shirakumo lichat/libera channel, my patreon, and other small, purpose-driven communities. But it's very possible I'll be leaving ELS behind me permanently after this year, cutting off even the last part of the community that used to be most of my world.
Regardless, I will still be working on my Lisp projects. If nothing else, one of the nice things about the looming tower of software I've built over all these years is that I am in control of the vast majority of it, and replacing any particular part I didn't write should it get enshittified is not that big of an endeavour.
Make no mistake though: I will continue to be increasingly outspoken and annoying about political matters that I consider important and relevant, and this will also be visible in the software I write, be that in licensing, ecosystem integration, or documentation.
I hope that more people will speak out publicly about their stance. It's important to show what you stand for, even if you're just a small part. What is considered "normal" and acceptable is only ever a matter of what people get to see, regardless of how prevalent that stance is among the population. Currently people are getting to see a lot of folks proudly and loudly making trash and littering it all over the place. This normalisation is dangerous, because it makes the average joes think it's OK for them to do it too, or even that they should be doing it.
Just the same way as any other social movement, you 🫵 play a role in it, and your voice matters. Whether you use your voice for the betterment of humans, for the betterment of the ghouls feeding off of us, or silently let the ghouls feed off of us.
A while ago, I decided that I’d like to test my intuition that Lisp (specifically implementations of Common Lisp) was not, in fact, bad at floating-point code and that the ease of designing languages in Lisp could make traditional Fortran-style array-bashing numerical code pretty pleasant to write.
I used an intentionally naïve numerical solution to a gravitating many-body system as a benchmark, so I could easily compare Lisp & C versions. The brief result is that the Lisp code is a little slower than C, but not much: Lisp is not, in fact, slow. Who knew?
The point here though, is that I wanted to dress up the array-bashing code so it looked a lot more structured. To do this I wrote a macro which hid what was in fact an array of (for instance) double floats behind a bunch of syntax which made it look like an array of structures. That macro took a couple of hours.
This was fine and pretty simple, but it only dealt with a single type for each conceptual array of objects, there was no inheritance and it was restricted in various other ways. In particular it really was syntactic sugar on a vector: there was no distinct implementational type at all. So I thought well, I could make it more general and nicer.
Big mistake.
The second system
Here is an example of what I wanted to be able to do (this is in fact the current syntax):
(define-soa-class example ()
((x :array t :type double-float)
(y :array t :type double-float)
(p :array t :type double-float :group pq)
(q :array t :type double-float :group pq)
(r :array t :type fixnum)
(s)))
This defines a class, instances of which have five array slots and one scalar slot. Of the array slots:
x and y share an array and will be neighbouring elements;
p and q share a different array, because the group option says they must not share with x and y;
r will be in its own array, unless the upgraded element type of fixnum is the same as that of double-float;
s is just a slot.
The implementation will tell you this:
> (describe (make-instance 'example :dimensions '(2 2)))
#<example 8010059EEB> is an example
[...]
dimensions (2 2)
total-size 4
rank 2
tick 1
its class example has a valid layout
it has 3 arrays:
index 0, element type double-float, 2 slots
index 1, element type (signed-byte 64), 1 slot
index 2, element type double-float, 2 slots
it has 5 array slots:
name x, index 0 offset 0
name y, index 0 offset 1
name r, index 1 offset 0
name p, index 2 offset 0
name q, index 2 offset 1
This is already too complicated: the ability to control sharing via groups is almost certainly never going to be useful: it’s only even there because I thought of it quite early on and never removed it.
The class definition macro then needs to arrange life so that enough information is available so that a macro can be written which turns indexed slot access into indexed array access of the underlying arrays which are secretly stored in instances, inserting declarations to make this as fast as possible: anything slower than explicit array access is not acceptable. This might (and does) look like this, for example:
As you can see from this, the resulting objects should be allowed to have rank other than 1. Inheritance should also work, including for array slots. Redefinition should be supported and obsolete macro expansions and instances at least detected.
In other words there are exactly two things I should have aimed at achieving: the ability to define fields of various types and have them grouped into (generally fewer) underlying arrays, and an implementational type to hold these things. Everything else was just unnecessary baggage which made the implementation much more complicated than it needed to be.
I had not finished making mistakes. The system needs to store some metadata about how slots map onto the underlying arrays, element types and so on, so the macro can use this to compile efficient code. There are two obvious ways to do this: use the property list of the class name, or subclass standard-class and store the metadata in the class. The first approach is simple, portable, has clear semantics, but it’s ‘hacky’; the second is more complicated, not portable, has unclear semantics1, but it’s The Right Thing2. Another wrong decision I made without even trying.
The only thing that saved me was that the nature of software is that you can only make a finite number of bad decisions in a finite time.
More bad decisions
I was not done. Early on, I thought that, well, I could make this whole thing be a shim around defstruct: single inheritance was more than enough, and obviously I could store metadata on the property list of the type name as described above. And there’s no nausea with multiple accessors or any of that nonsense.
But, somehow, I found writing a thing which would process the (structure-name ...) case of defstruct too painful, so I decided to go for the shim-around-defclass version instead. I even have a partly-complete version of the defstructy code which I abandoned. Another mistake.
I also decided that The Right Thing was to have the system support objects of rank 0. That constrains the underlying array representation (it needs to use rank \(n+1\) arrays for an object of rank \(n\)) in a way which I thought for a long time might limit performance.
Things I already knew
At any point during the implementation of this I could have told you that it was too general and the implementation was going to be too complicated for no real gain. I don’t know why I made so many bad choices.
The whole process took weeks and I nearly just gave up several times.
The light at the end of the tunnel
Or: all-up testing.
Eventually, I had a thing I thought might work. The macro syntax was a bit ugly (that macro still exists, with a different name) but it seemed to work. But since the whole purpose of the thing was performance, that needed to be checked. I wasn’t optimistic.
What I did was to write a version of my naïve gravitational many-body system using the new code, based closely on the previous one. The function that updates the state of the particles looks like this:
And it not only worked, the performance was very close to the previous version, straight out of the gate. The syntax is not as nice as that of the initial, quick-and-dirty version, but it is much more general, so I think that’s worth it on the whole.
There have been problems since then: in particular the dependency on when classes get defined. It will never be as portable as I’d like because of the unnecessary MOP dependencies3, but it is usable and quick4.
Was it worth it? May be, but it should have been simpler.
Nothing that uses the AMOP MOP is ever The Right Thing, because the whole thing was designed by people who were extremely smart, but still not as smart as they needed to be and thought they were. It’s unclear if any MOP for CLOS can ever be satisfactory, in part because CLOS itself suffers from the same smart-but-not-smart-enough problem to a large extent not helped by bring dropped wholesale into CL at the last minute: by the time CL was standardised people had written large systems in it, but almost nobody had written anything significant using CLOS, let alone the AMOP MOP. ↩
A mistake I somehow managed to avoid was using the whole slot-definition mechanism the MOP wants you to use. ↩
All Elementary Functions from a Single Operator is a paper by Andrzej Odrzywołek that has been making rounds on the internet lately, being called everything from a “breakthrough” to “groundbreaking”. Some are going as far as to suggest that the entire foundations of computer engineering and machine learning should be re-built as a result of this. The paper says that the function
$$
E(x,y) := \exp x - \log y
$$
together with variables and the constant $1$, which we will call EML terms, are sufficient to express all elementary functions, and proceeds to give constructions for many constants and functions, from addition to $\pi$ to hyperbolic trigonometry.
I think the result is neat and thought-provoking. Odrzywołek is explicit about his definition of “elementary function”. His Table 1 fixes “elementary” as 36 specific symbols, and under that definition his theorem is correct and clever, so long as we accept some of his modifications to the conventional $\log$ function and do arithmetic with infinities.
My concern is that the word “elementary” in the title carries a much broader meaning in standard mathematical usage. Odrzywołek recognizes this, saying little more than “[t]hat generality is not needed here” and that his work takes “the ordinary scientific-calculator point of view”. He does not offer further commentary.
What is this more general setting, and does his claim still hold? In modern pure mathematics, dating back to the 19th century, the definition of “elementary function” has been well established. We’ll get to a definition shortly, but to cut to the chase, the titular result does not hold in this setting. As such, in layman’s terms, I do not consider the “Exp-Minus-Log” function to be the continuous analog of the Boolean NAND gate or the universal quantum CCNOT/CSWAP gates.
The rough TL;DR is this: Elementary functions typically include arbitrary polynomial root functions, and EML terms cannot express them. Below, I’ll give a relatively technical argument that EML terms are not sufficient to express what I consider standard elementary functions.
To avoid any confusion, the purpose of this blog post is manifold:
To elucidate what many mathematicians consider to be an “elementary function”, which is the foundation for a variety of rich and interesting math (especially if you like computer science).
To prove a result about EML terms using topological Galois theory.
To demonstrate how this result may be used to show an elementary function not expressible by EML terms.
This blog post is not a refutation of Odrzywołek’s work, though the title might be considered just as clickbait (and accurate) as his, depending on where you sit in the hall of mathematics and computation.
Disclaimer: I audited graduate-level mathematics courses almost 20 years ago, and I am not a professional mathematician. Please email me if my statements are clumsy or incorrect.
The 19th century is where all modern understanding of elementary functions was developed, Liouville being one of the big names with countless theorems of analysis and algebra named after him. One such result is about integration: do the outputs of integrals look the same as their inputs? Well, what does “input” and “look the same” mean? Liouville defined a class of functions called elementary functions, and said that the integral of an elementary function will sometimes be elementary, and when it is, it will always resemble the input in a specific way, plus potential extra logarithmic factors.
Since then, elementary functions have been defined by starting with rational functions and closing under arithmetic operations, composition, exponentiation, logarithms, and polynomial roots. While EML terms are quite expressive, they are unable to capture the “polynomial roots” in full generality. We will show this by using Khovanskii’s topological Galois theory: the monodromy group of a function built from rational functions by composition with $\exp$ and $\log$ is solvable. For anybody that has studied Galois theory in an algebra course, this will be familiar, as the destination here is effectively the same, but with more powerful intermediate tooling to wrangle exponentials and logarithms.
First, let’s be more precise by what we mean by an EML term and by a standard elementary function.
Definition (EML Term): An EML term in the variables $x_1,\dots,x_n$ is any expression obtained recursively, starting from $\{1, x_1,\dots,x_n\}$, by the rule
$$
T,S \mapsto \exp T-\log S.
$$
Each such term, evaluated at a point where all the $\log$ arguments are nonzero, determines an analytic germ; we take $\mathcal T_n$ to be the class of germs representable this way, together with their maximal analytic continuations.
Definition (Standard Elementary Function): The standard elementary functions $\mathcal{E}_n$ are the smallest class of multivalued analytic functions on domains in $\mathbb{C}^n$ containing the rational functions and closed under
arithmetic operations and composition,
exponentiation and logarithms,
algebraic adjunctions: if $P(Y)\in K[Y]$ is a polynomial whose coefficients lie in a previously constructed class $K$, then any local branch of a solution of $P(Y)=0$ is admitted.
What we will show is that the class of elementary functions defined this way is strictly larger than the class induced by EML terms.
Lemma: Every EML term has solvable monodromy group. In particular, if $f\in\mathcal T_n$ is algebraic over $\mathbb C(x_1,\dots,x_n)$, then its monodromy group is a finite solvable group.
Proof: We prove by induction on EML term construction. Constants and coordinate functions have trivial monodromy.
For the inductive step, suppose $f = \exp A-\log B$ with $A,B\in\mathcal T_n$, and assume that $\mathrm{Mon}(A)$ and $\mathrm{Mon}(B)$ are solvable. We argue in three steps.
Step 1: $\mathrm{Mon}(\exp A)$ is solvable. The germs of $\exp A$ are images under $\exp$ of the germs of $A$, with germs of $A$ differing by $2\pi i\mathbb Z$ collapsing to the same value. So there is a surjection $\mathrm{Mon}(A)\twoheadrightarrow\mathrm{Mon}(\exp A)$, and a quotient of a solvable group is solvable.
Step 2: $\mathrm{Mon}(\log B)$ is solvable. At a generic point $p$, germs of $\log B$ are parameterized by pairs $(b,k)$ where $b$ is a germ of $B$ at $p$ and $k\in\mathbb Z$ selects the branch of $\log$. A loop $\gamma$ acts by
$$
(b,k)\mapsto\bigl(\rho_B(\gamma)(b), k+n(\gamma,b)\bigr),
$$
where $\rho_B(\gamma)$ is the monodromy action of $\gamma$ on germs of $B$, and $n(\gamma,b)\in\mathbb Z$ is the winding number around $0$ of the analytic continuation of $b$ along $\gamma$. The projection $\mathrm{Mon}(\log B)\to\mathrm{Mon}(B)$ onto the first component is a surjective homomorphism. Its kernel consists of the elements of $\mathrm{Mon}(\log B)$ induced by loops $\gamma$ with $\rho_B(\gamma)=\mathrm{id}$, which then act only by integer shifts on the $k$-coordinate. Let $S_B$ be the set of germs of $B$ at $p$. For each $b\in S_B$, such a loop determines an integer shift $n(\gamma,b)$, so the kernel embeds in the direct product $\mathbb Z^{S_B}$. In particular, the kernel is abelian. Hence $\mathrm{Mon}(\log B)$ is an extension of $\mathrm{Mon}(B)$ by an abelian group, and extensions of solvable groups by abelian groups are solvable.
Step 3: $\mathrm{Mon}(f)$ is solvable. At a generic point, a germ of $f=\exp A-\log B$ is obtained by subtraction from a pair (germ of $\exp A$, germ of $\log B$), and analytic continuation acts componentwise on such pairs. This gives a surjection of $\pi_1$ onto some subgroup
$$
H \le \mathrm{Mon}(\exp A)\times\mathrm{Mon}(\log B),
$$
and, since $f$ is obtained from the pair by subtraction, this descends to a surjection $H\twoheadrightarrow\mathrm{Mon}(f)$. So $\mathrm{Mon}(f)$ is a quotient of a subgroup of a direct product of solvable groups, hence solvable.
The second statement of the lemma follows: an algebraic function has finitely many branches, so its monodromy group is finite; a solvable group that is finite is, well, finite and solvable. ∎
Proof: $\mathcal E_n$ is closed under algebraic adjunction, so any local branch of an algebraic function is elementary. In particular, a branch of a root of the generic quintic
$$
f^5+a_1f^4+a_2f^3+a_3f^2+a_4f+a_5=0
$$
is elementary.
Suppose for contradiction that at some point $p$ a germ of a branch of this root agrees with a germ of an EML term $T$. By uniqueness of analytic continuation, the Riemann surfaces obtained by maximally continuing these two germs coincide, so in particular their monodromy groups coincide. The monodromy group of the generic quintic is $S_5$, which is not solvable. But by the lemma, the monodromy group of any EML term is solvable. Contradiction.
Hence $\mathcal T_n$ is a strict subset of $\mathcal E_n$. ∎
Edit (15 April 2026): This article used to have an example proving that the real and complex absolute value cannot be expressed over their entire domain as EML terms under the conventional definition of $\log$. I wrote it to emphasize that Odrzywołek’s approach required mathematical “patching” in order to work as intended. However, it ended up more distracting than illuminating, and was tangential to the point about the definition of “elementary”, so it has been removed.
A couple of weeks ago I released FSet 2.4.0, which brought a CHAMP implementation of bags, filling out the suite of CHAMP types. 🚀 FSet users should have a look at the release page, as it also contained a number of bug fixes and minor changes.
I've since released v2.4.1 and v2.4.2, with some more bug fixes.
But the big news is the book! It brings together all the introductory material I have written, plus a lot more, along with a complete API Reference chapter.
FSet is now in the state I decided last summer I wanted to get it into: faster, better tested and debugged, more feature-complete, and much better documented than it has ever been in its nearly two decades of existence. I am, of course, very much hoping that these months of work have made the library more interesting and accessible to CL programmers who haven't tried it yet. I am even hoping that its existence helps attract newcomers to the CL community. Time will tell!
When you work on projects that become even slightly complex it is a matter of
time until you run into problems where the specific version of a particular
library becomes important. This happens in most, if not all, programming
languages.
In the Common Lisp environment Quicklisp has become the de facto standard for
loading libraries, including fetching and loading their dependencies. Quicklisp
distributes libraries in "distributions" which are point-in-time snapshots of
all the known and working libraries at the time of distribution creation.
An advantage of this approach is that you are guaranteed that all libraries
available in the distribution can be loaded with any of the others. Some
disadvantages are that 1) if a library was included in an older distribution
but no longer loads cleanly, it gets removed from the distribution, and 2)
libraries are only added or updated when a new distribution is cut.
Though libraries can be put in ~/quicklisp/local-projects/ in order to
supplement or override those in the distribution, Quicklisp
does not provide any mechanism for pinning the state of
~/quicklisp/local-projects/.
Some Quicklisp attributes:
All libraries in a distribution can be loaded with any of the others. Those
that no longer do are removed from the distribution.
Libraries are only added or updated at distribution cutting time.
You specify a single distribution version, not individual library
versions. The distribution is used globally, across all projects and
across all lisp implementations.
Libraries can be loaded from ~/quicklisp/local-projects/. Anything
there will override the version in the distribution.
Nothing about the ~/quicklisp/local-projects/ content can be
specified using Quicklisp. It needs to be managed outside of Quicklisp.
Libraries are loaded from the current Quicklisp distribution. There is no
way to specify which distribution version a particular project must use.
Quicklisp can create a bundle of all the loaded systems that can be
committed with the project code and used from there rather than the
distribution, i.e. vendoring.
The source code for libraries included in a distribution are stored in a
dedicated location for Quicklisp, they are not read from the original source
repo.
Depending on your situation these attributes may be positive, negative or
irrelevant.
There are projects like Ultralisp that have different philosophies regarding
the distribution content but they still depend on Quicklisp for all other
aspects. Thus they share most of the above attributes.
Since my previous post on this topic much has changed in the
library version arena. There are now many projects that address different
aspects of the above list; the topic of vendoring has gained momentum; and Qlot
has changed a lot, to the extent that some code samples in older posts no
longer work.
Vendoring is the idea that all the libraries your project depend on are
actually part of your project and as such should be committed as part of the
project code. Both Quicklisp and Qlot support this with QL:bundle and
QLOT:bundle, and the Vend tool is entirely focused on vendoring.
The significant changes in Qlot broke my development workflow. Since I now had
to spend time fixing this it was a good opportunity to evaluate some of the
other library versioning tools. The issues that made me hesitant to adapt to
the new Qlot without considering other options are:
Roswell: Qlot pushes hard for using Roswell. That ads Roswell as another
intermediary and dependency in an already complex process.
The Qlot documentation is heavily biased towards using it as an external tool
rather than through the REPL. Previously I used Qlot from the REPL and wanted
to continue doing so if possible.
Qlot is developed on SBCL which means that any issues in CCL take longer to
be discovered and fixed. As I mainly use CCL it is something to keep in mind.
The documentation proposes that lisp be started as a subprocess of Qlot,
e.g. $ qlot exec ros emacs or $ qlot exec ccl. This is to ensure that the
lisp is properly configured to use the project local Quicklisp. This is a
brittle solution because the standard lisp REPL is then no longer
sufficient. When you forget to start lisp this way Quicklisp will load the
wrong libraries without any indication, potentially causing subtle bugs which
are normally absent.
Using QLOT:quickload rather than QL:quickload always bugged me for
similar reasons. It is a non-standard way to do a standard thing. Forgetting
to do it is easy and then you have the wrong libraries loaded.
I evaluated many of the other version management tools and came to the
conclusion that Qlot is the closest to what I wanted and I set off trying to
find a workflow that will adhere to my requirements listed here:
Does not involve Roswell
Works with CCL
Works inside the REPL of a lisp loaded without any funny requirements
Gives me 100% certainty that the correct versions of all libraries are
loaded, without having to interrogate (asdf:system-relative-pathname) for
each.
After some fiddling with Qlot I learned that:
Qlot installs a complete and independent Quicklisp inside your project
directory. This Quicklisp has no dependence, relation or knowledge about the
global Quicklisp.
$ qlot exec ccl mostly arranges things such that Quicklisp is loaded from
the project local installation. If you can arrange for that to happen
without using Qlot then you can use start your lisp normally.
When the project local Quicklisp is loaded it doesn't know about the global
or any other project local Quicklisps. This gives the 100% certainty of
where libraries were loaded from.
When the project local Quicklisp is loaded you use it exactly like you would
the global one. That is, QL:quickload and not QLOT:quickload, nor do you
use any other Qlot wrappers.
Qlot does not need to be present in your lisp image at all.
Loading Qlot inside you current REPL doesn't work well because:
The Qlot REPL API is still in development.
Doing this loads Qlot from the global Quicklisp instead of the project
local one. Distribution version mismatches between the two Quicklisps
could trigger issues with Qlot itself. It also voids the certainty of
library location.
Having Qlot as a standalone executable outside of your lisp image puts it on
the same plane as other tools used for development such as make or git. It
then doesn't matter which implementation it prefers because it doesn't
affect your choices.
Qlot has gained the ability to bundle libraries in case you want to go the
vendoring route.
Roswell is not needed for any of the above.
New workflow
Combining my requirements and my new understanding of Qlot, I modified my
workflow for pinning library versions to be:
Qlot executable must be available in your path.
Specify the distribution and library versions in qlfile.
qlot install at the CLI.
Load lisp without executing init scripts, e.g. ccl -n.
Load Quicklisp from the project local installation.
(load "PROJECT-PATH/.qlot/setup.lisp")
Use Quicklisp as before.
(ql:quickload :alexandria)
If you would like to vendor your libraries then:
Specify the distribution and library versions in qlfile.
qlot install
qlot bundle
git commit
ccl
(load PROJECT-PATH/.bundle-libs/setup.lisp)
Qlot tasks
All Qlot related tasks such as initialising a project, installing libraries,
upgrading libraries, etc must be performed in the CLI using the Qlot
executable. These happen relatively infrequently and inside the REPL Qlot does
not feature.